一、内存管理初步
通过前面的文章我们知道计算机加电后进入BIOS自检,BIOS自检完成到0x7c00位置执行主引导扇区的代码,主引导扇区加载了0x1000处的内核加载器,内核加载器引导位于0x10000处的内核程序, 1MB往后即0x100000后的内存区域属于32位可用区域。在80386/80486中内存分页都是以4k为单位。
#define ZONE_VALID 1 // ards 可用内存区域
#define ZONE_RESERVED 2 // ards 不可用区域
#define IDX(addr) ((u32)addr >> 12) // 获取 addr 的页索引
typedef struct ards_t // 定义ards结构体
{
u64 base; // 内存基地址
u64 size; // 内存长度
u32 type; // 类型
} _packed ards_t;
u32 memory_base = 0; // 可用内存基地址,应该等于 1M
u32 memory_size = 0; // 可用内存大小
u32 total_pages = 0; // 所有内存页数
u32 free_pages = 0; // 空闲内存页数
#define used_pages (total_pages - free_pages) // 已用页数
void memory_init(u32 magic, u32 addr) // 内存初始化,入参分别是魔数和ards的地址
{
u32 count;
ards_t *ptr;
if (magic == ONIX_MAGIC) // 如果是 onix loader 进入的内核
{
count = *(u32 *)addr; // ards是在内核加载器中检测的
ptr = (ards_t *)(addr + 4);
for (size_t i = 0; i < count; i++, ptr++)
{
LOGK("Memory base 0x%p size 0x%p type %d\n",
(u32)ptr->base, (u32)ptr->size, (u32)ptr->type);
if (ptr->type == ZONE_VALID && ptr->size > memory_size)
{
memory_base = (u32)ptr->base; // 获取最后一个可用区的地址和大小
memory_size = (u32)ptr->size;
}
}
}
else
{
panic("Memory init magic unknown 0x%p\n", magic);
}
LOGK("ARDS count %d\n", count);
LOGK("Memory base 0x%p\n", (u32)memory_base);
LOGK("Memory size 0x%p\n", (u32)memory_size);
assert(memory_base == MEMORY_BASE); // 内存开始的位置为 1M
assert((memory_size & 0xfff) == 0); // 要求按页对齐
total_pages = IDX(memory_size) + IDX(MEMORY_BASE);
free_pages = IDX(memory_size);
LOGK("Total pages %d\n", total_pages);
LOGK("Free pages %d\n", free_pages);
}
如上所示,在对内存初始化时,获取了内核加载器中执行的内存检测结果。运行结果如下:
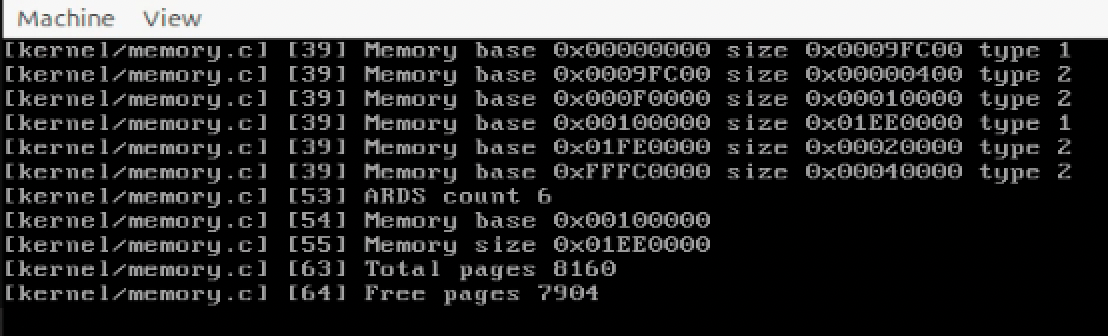 最后一个可用区是从1M的位置开始,一共8160个可用内存页(包含1M以内的内存页)。可用内存页是7904个,这是1MB以后的可用内存页。
最后一个可用区是从1M的位置开始,一共8160个可用内存页(包含1M以内的内存页)。可用内存页是7904个,这是1MB以后的可用内存页。
二、物理内存管理
从可用内存开始的位置分配一些页用于管理物理内存,每个物理页使用一个字节表示引用数量,意味着一个物理页最多被引用 255 次, 即一个页可以被多个进程使用。提供两个函数get_page和put_page分别用于申请和释放一页内存。实现如下:
#define PAGE(idx) ((u32)idx << 12) // 获取页索引 idx 对应的页开始的位置
void memory_map_init()
{
memory_map = (u8 *)memory_base; // 在1M内存的位置初始化物理内存数组
memory_map_pages = div_round_up(total_pages, PAGE_SIZE); // 计算物理内存数组占用的页数,1页能管理4k页内存
LOGK("Memory map page count %d\n", memory_map_pages);
free_pages -= memory_map_pages; // 可用页减去内存管理占用的页
memset((void *)memory_map, 0, memory_map_pages * PAGE_SIZE); // 清空物理内存数组
start_page = IDX(MEMORY_BASE) + memory_map_pages; // 前 1M 的内存位置 以及 物理内存数组已占用的页,已被占用
for (size_t i = 0; i < start_page; i++)
{
memory_map[i] = 1;
}
LOGK("Total pages %d free pages %d\n", total_pages, free_pages);
}
static u32 get_page() // 分配一页物理内存
{
for (size_t i = start_page; i < total_pages; i++)
{
if (!memory_map[i]) // 如果物理内存没有占用
{
memory_map[i] = 1;
free_pages--;
assert(free_pages >= 0);
u32 page = ((u32)i) << 12;
LOGK("GET page 0x%p\n", page);
return page;
}
}
panic("Out of Memory!!!");
}
static void put_page(u32 addr) // 释放一页物理内存
{
ASSERT_PAGE(addr);
u32 idx = IDX(addr);
assert(idx >= start_page && idx < total_pages); // idx 大于 1M 并且 小于 总页面数
assert(memory_map[idx] >= 1); // 保证只有一个引用
memory_map[idx]--; // 物理引用减一
if (!memory_map[idx]) // 若为 0,则空闲页加一
{
free_pages++;
}
assert(free_pages > 0 && free_pages < total_pages);
LOGK("PUT page 0x%p\n", addr);
}
如上所示,使用1M后最开始的位置来管理所有页,勇敢get_page来申请一页,put_page释放数据页。
三、内存映射原理
内存管理机制有分段和分页两种,在全局描述符中用到过分段,每段包含起始位置大小和内存属性,但是在平坦模型中内存只分一个段,也就是不分段。分页也就是把物理内存分成4k一页的大小。接下来看一下内存映射机制,如图:
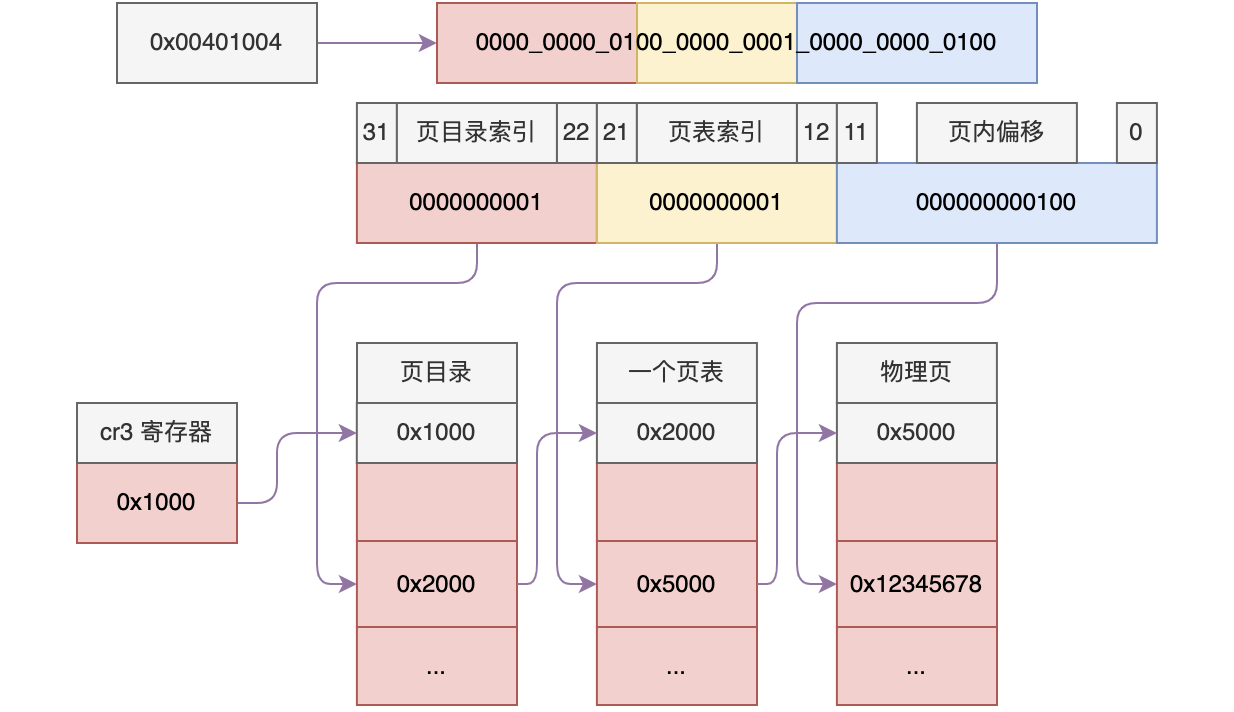 如图,假设一个有虚拟内存地址 0x00401004, 它的32位二进制被划分为10位、10位、12位。第一个10位是页目录的索引,中间10位是页表索引,最后12位是页内偏移。页目录存储到cr3寄存器中。 如图假设cr3寄存器存的值是0x1000, 首先从0x1000这页的第1个位置找到页表0x2000, 然后从0x2000这页的第一个位置找到0x5000这个物理页,最后从0x5000这页的第8个位置找到存储的数据。下面说一下几个地址的概念:
如图,假设一个有虚拟内存地址 0x00401004, 它的32位二进制被划分为10位、10位、12位。第一个10位是页目录的索引,中间10位是页表索引,最后12位是页内偏移。页目录存储到cr3寄存器中。 如图假设cr3寄存器存的值是0x1000, 首先从0x1000这页的第1个位置找到页表0x2000, 然后从0x2000这页的第一个位置找到0x5000这个物理页,最后从0x5000这页的第8个位置找到存储的数据。下面说一下几个地址的概念:
- 逻辑地址: 程序访问的地址,形式是 段选择子:偏移量,例如mov eax, [ds:0x1000]
- 线性地址: 程序访问的地址 + 描述符的基地址,逻辑地址通过GDT转换后的地址
- 物理地址: 实际内存的位置,在 Linux 中,虚拟地址就是线性地址。
- 虚拟地址: 操作系统抽象出来给进程用的地址空间,
在平坦模型中,逻辑地址和线性地址是相同的,对于我们的内核,虚拟地址和线性地址也是一样的。内存映射是将线性地址转换为物理地址的过程。
3.1、内存分页机制
内存分页机制第一个作用了保证多个进程可以访问同一个虚拟地址(映射到不同的物理地址),第二个作用可以使硬盘模拟内存。32位可以访问4G内存,分为1M = 2**20个页。做线性地址和物理地址的一一映射关系,这个映射关系存储在内存中,就需要20位的数据结构,由于系统中没有 20bit 的数据结构,所以用 32bit 的数据结构来存,那么就需要一个如下的数组来存储:
u32 page_table[1 << 20];
其中 1 « 20 就是 1M, 由于总共有 1M 个页,一页占用了 4B(u32是四字节),所以这个数组尺寸是 4M,这个数组也就是页表;这个数组也存储在内存中,4M = 1024 * 4K,也就是需要 1024 个页来存储;
由于每个进程都需要一个页表来映射内存,如果直接用这种方式的话,每个进程都需要至少 4M 的内存来存储页表,但是,并不是所有的进程都用到所有 4G 的空间,所以这种方式很不划算,而且 386 的年代,内存比较小,显然不能这样干。所以就有了页目录,用来表示这 1024 个页。一页页表用 4B 表示,恰好是 4KB,页目录 恰好 占用一页的内存;
如果进程只用到了很少的内存的话,就可以只用两个页来表示,这样可以表示 4M 的内存,一页页目录,一页页表,总共用到了 8K,比上面的 4M 节约了不少。当然,如果进程确实用到了全部 4G 的空间,那么就会比 4M 再多一页页目录,不过一般进程不会用到所有的内存,而且操作系统也不允许;
表示一页 20bit 就够了,但是却用了 32 bit,另外的 12 bit 用来表示这页内存的属性,以下结构体说明页表和页目录的32位分别都什么作用
typedef struct page_entry_t
{
u8 present : 1; // 在内存中
u8 write : 1; // 0 只读 1 可读可写
u8 user : 1; // 1 所有人 0 超级用户 DPL < 3
u8 pwt : 1; // page write through 1 直写模式,0 回写模式
u8 pcd : 1; // page cache disable 禁止该页缓冲
u8 accessed : 1; // 被访问过,用于统计使用频率
u8 dirty : 1; // 脏页,表示该页缓冲被写过
u8 pat : 1; // page attribute table 页大小 4K/4M
u8 global : 1; // 全局,所有进程都用到了,该页不刷新缓冲
u8 ignored : 3; // 该安排的都安排了,送给操作系统吧
u32 index : 20; // 页索引
} _packed page_entry_t;
这个结构体是有意构造的,恰好占 4 个字节,一页内存可以表示下面这样一个数组;
page_entry_t page_table[1024];
3.2、内存映射
内存映射用到两个寄存器,一个是CR3存储页目录的索引。第二个是CR0寄存器,启用分页需要将CR0寄存器的第31位置1。以下为内存映射的步骤:
- 首先准备一个页目录,若干页表
- 将映射的地址写入页表,将页表写入页目录
- 将页目录写入 cr3 寄存器
- 将 cr0 最高位 (PG) 置为 1,启用分页机制
一个实际的要求就是 映射完成后,低端 1M 的内存要映射的原来的位置,因为内核放在那里,映射完成之后就可以继续执行了。接下来看内存映射的核心代码:
// 初始化页表项
static void entry_init(page_entry_t *entry, u32 index)
{
*(u32 *)entry = 0;
entry->present = 1;
entry->write = 1;
entry->user = 1;
entry->index = index;
}
#define KERNEL_PAGE_DIR 0x200000 // 内核页目录,这里是随便找的位置
#define KERNEL_PAGE_ENTRY 0x201000 // 内核页表
void mapping_init()
{
page_entry_t *pde = (page_entry_t *)KERNEL_PAGE_DIR;
memset(pde, 0, PAGE_SIZE);
entry_init(&pde[0], IDX(KERNEL_PAGE_ENTRY)); // 设置页目录,页目录索引指向页表
page_entry_t *pte = (page_entry_t *)KERNEL_PAGE_ENTRY;
memset(pte, 0, PAGE_SIZE);
page_entry_t *entry;
for (size_t tidx = 0; tidx < 1024; tidx++) // 页表只用了一个页即4K, 表示1024个页(一个页是4B),即映射4M内存
{ // 访问4G内存需要1M个页来表示页表
entry = &pte[tidx];
entry_init(entry, tidx);
memory_map[tidx] = 1; // 设置物理内存数组,该页被占用
}
set_cr3((u32)pde); // 设置 cr3 寄存器
enable_page(); // 分页有效 将CR0寄存器的31位置1
}
如上:我们找了两个位置做内核的页目录和页表的映射。这里省略了操作寄存器的函数实现,都是通过内联汇编实现的。
四、内存映射调试
可以在内存映射后打bochs魔数断点,查看映射的内容情况。如下:
 如图所示,页索引位置的数据是 20 10 07。07对应的是属性的后三位在内存中,可读可写。所有人可访问。在看下页表位置的内存
如图所示,页索引位置的数据是 20 10 07。07对应的是属性的后三位在内存中,可读可写。所有人可访问。在看下页表位置的内存
 接下来就可以打印分页了,分页后页表信息如下:
接下来就可以打印分页了,分页后页表信息如下:
 如图:线性地址0~4M被映射到了物理位置的0~4M。 因为我们只映射了前4M内存,因此此时如果尝试访问4M以后的内存,将会触发缺页异常。并将造成缺页异常的内存地址存入到cr2寄存器中。
如图:线性地址0~4M被映射到了物理位置的0~4M。 因为我们只映射了前4M内存,因此此时如果尝试访问4M以后的内存,将会触发缺页异常。并将造成缺页异常的内存地址存入到cr2寄存器中。
「真诚赞赏,手留余香」
 WangFuJie Blog
WangFuJie Blog
真诚赞赏,手留余香
使用微信扫描二维码完成支付
