一、磁盘电梯调度算法
由于磁盘性能的主要瓶颈在磁盘的寻道时间,也就是磁头臂的移动时间,所以要尽可能避免磁头臂的移动。电梯算法的作用是让磁头的综合移动距离最小,从而改善磁盘访问时间。
假设我们的磁盘有7个磁道,由内往外分别是1~7。当前磁头臂在2磁道,来了一个需求需要读取6磁道,又来了一个需求读取4磁道,如果按照先来先服务,那磁头臂应该由2摆动到6再摆动到4,这样磁头臂的移动距离就比较大,电梯算法解决的就是这个问题,让磁头臂从2摆动到4再摆动到6。
电梯算法简单来说就是磁头沿当前方向移动,依次处理沿途的请求。当到达边界后再反向移动,继续处理沿途的请求。这样减少磁头来回跳跃,提高整体吞吐量。
1.1 电梯算法的实现
我们这里介绍下电梯算法的实现思路,即把磁盘读写请求添加到一个链表,每次插入请求进行一次插入排序。然后从链表表找到合适的请求方法。
// 定义磁盘的寻道方向,在设备结构体中增加一个寻道方向。默认初始化为上楼
#define DIRECT_UP 0 // 上楼
#define DIRECT_DOWN 1 // 下楼
// 获得下一个请求
static request_t *request_nextreq(device_t *device, request_t *req)
{
list_t *list = &device->request_list;
if (device->direct == DIRECT_UP && req->node.next == &list->tail)
{
device->direct = DIRECT_DOWN;
}
else if (device->direct == DIRECT_DOWN && req->node.prev == &list->head)
{
device->direct = DIRECT_UP;
}
void *next = NULL;
if (device->direct == DIRECT_UP)
{
next = req->node.next;
}
else
{
next = req->node.prev;
}
if (next == &list->head || next == &list->tail)
{
return NULL;
}
return element_entry(request_t, node, next);
}
// 块设备请求
void device_request(dev_t dev, void *buf, u8 count, idx_t idx, int flags, u32 type)
{
device_t *device = device_get(dev);
assert(device->type = DEV_BLOCK); // 是块设备
idx_t offset = idx + device_ioctl(device->dev, DEV_CMD_SECTOR_START, 0, 0);
if (device->parent)
{
device = device_get(device->parent);
}
request_t *req = kmalloc(sizeof(request_t));
req->dev = dev;
req->buf = buf;
req->count = count;
req->idx = offset;
req->flags = flags;
req->type = type;
req->task = NULL;
LOGK("dev %d request idx %d\n", req->dev, req->idx);
bool empty = list_empty(&device->request_list); // 判断列表是否为空
list_insert_sort(&device->request_list, &req->node, element_node_offset(request_t, node, idx)); // 将请求插入链表
if (!empty) // 如果列表不为空,则阻塞,因为已经有请求在处理了,等待处理完成;
{
req->task = running_task();
task_block(req->task, NULL, TASK_BLOCKED);
}
do_request(req);
request_t *nextreq = request_nextreq(device, req);
list_remove(&req->node);
kfree(req);
if (nextreq)
{
assert(nextreq->task->magic == ONIX_MAGIC);
task_unblock(nextreq->task);
}
}
如上所示,我们贴出了部分的实现代码。在上一篇文章中,对于块设备请求,我们将请求插入到链表并且先到先服务。这里就通过改为电梯算法来提升效率。我们创建三个测试进程,三个测试进程分别做一下test系统调用进行磁盘访问。三个线程分别访问1,5, 3扇区,通过调试就可以发现块设备最后是按照1,3,5进行的处理的请求。
二、哈希表
哈希表:散列表,以关键字和数据 (key - value) 的形式直接进行访问的数据结构。可以通过拉链法来解决哈希冲突的问题。我们这里通过哈希来实现高速缓冲,哈希函数如下:
#define BLOCK_SIZE 1024 // 块大小
#define SECTOR_SIZE 512 // 扇区大小
#define BLOCK_SECS (BLOCK_SIZE / SECTOR_SIZE) // 一块占 2 个扇区
typedef struct buffer_t
{
char *data; // 数据区
dev_t dev; // 设备号
idx_t block; // 块号
int count; // 引用计数, 表示有多少使用者在使用这个buffer
list_node_t hnode; // 哈希表拉链节点 查找用途(哈希表链表,快速定位某个 (dev, block) 的 buffer)
list_node_t rnode; // 缓冲节点 管理用途(替换/遍历链表,方便调度和释放)
lock_t lock; // 锁
bool dirty; // 是否与磁盘不一致
bool valid; // 是否有效
} buffer_t;
#define HASH_COUNT 31 // 应该是个素数
static list_t hash_table[HASH_COUNT]; // 缓存哈希表
u32 hash(dev_t dev, idx_t block)
{
return (dev ^ block) % HASH_COUNT;
}
static buffer_t *get_from_hash_table(dev_t dev, idx_t block) // 从哈希表中找指定设备的块儿
{
u32 idx = hash(dev, block); // 获取hash值
list_t *list = &hash_table[idx]; // 得到hash的链表
buffer_t *bf = NULL;
for (list_node_t *node = list->head.next; node != &list->tail; node = node->next) // 遍历链表
{
buffer_t *ptr = element_entry(buffer_t, hnode, node);
if (ptr->dev == dev && ptr->block == block)
{
bf = ptr; // 如果找到,就返回buffer的指针
break;
}
}
if (!bf)
{
return NULL;
}
if (list_search(&free_list, &bf->rnode)) // 如果 bf 在缓冲列表中,则移除
{
list_remove(&bf->rnode);
}
return bf;
}
static void hash_locate(buffer_t *bf) // 将 bf 放入哈希表
{
u32 idx = hash(bf->dev, bf->block);
list_t *list = &hash_table[idx];
assert(!list_search(list, &bf->hnode));
list_push(list, &bf->hnode);
}
static void hash_remove(buffer_t *bf) // 将 bf 从哈希表中移除
{
u32 idx = hash(bf->dev, bf->block);
list_t *list = &hash_table[idx];
assert(list_search(list, &bf->hnode));
list_remove(&bf->hnode);
}
如上即为buffer的哈希表实现。我们这里固定了填充因子是31。
三、高速缓冲
一般来说,性能不同的两个系统之间应该有一个缓冲区;文件系统以块为单位访问磁盘,块一般是 2的n次方 个扇区。其中 4K 比较常见;这里我们使用 1K,也就是 2 个扇区作为一块。高速缓冲将块存储在哈希表中,以降低对磁盘的访问频率,提高性能。
高速缓冲需要用到内存区域,我们调整使用8M~12M的内存区域作为高速缓冲。也就是磁盘读出的扇区会存储到这个位置,这样对扇区的多次读写就可以在内存中进行,最后只需要一次刷回磁盘。
接下来看高速缓存的实现,这里内核的内存需要改为16M,因为高速缓存需要使用4M,另外4M预留给虚拟磁盘。这样需要再调整下内存布局,如下:
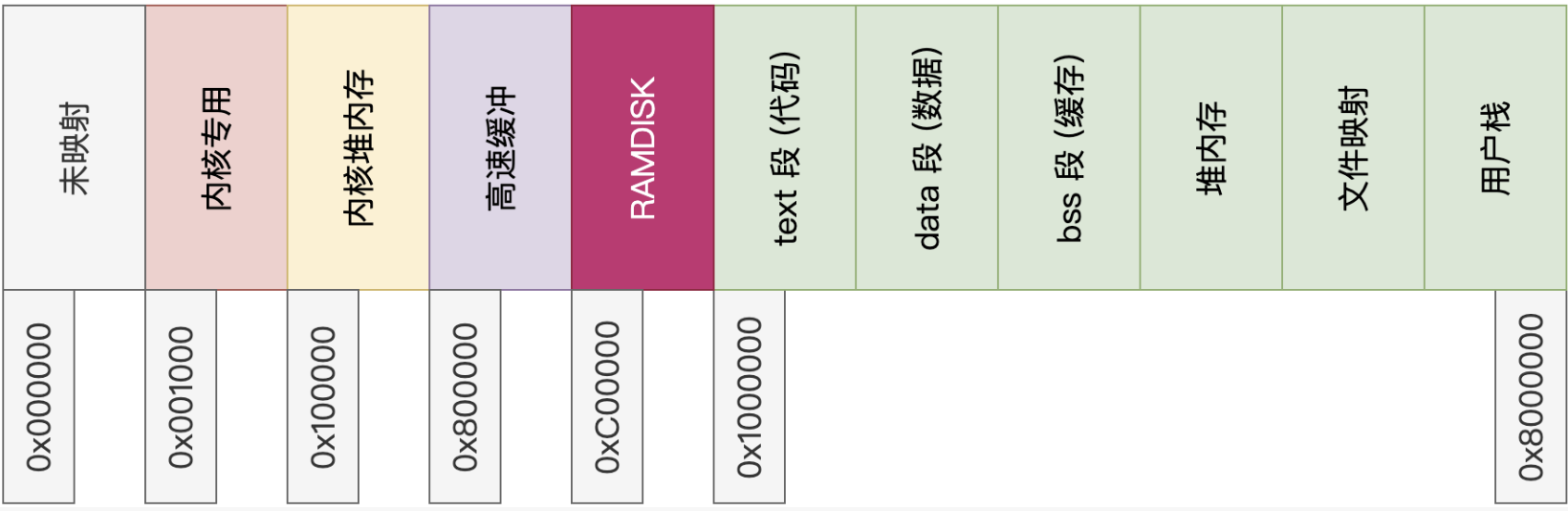
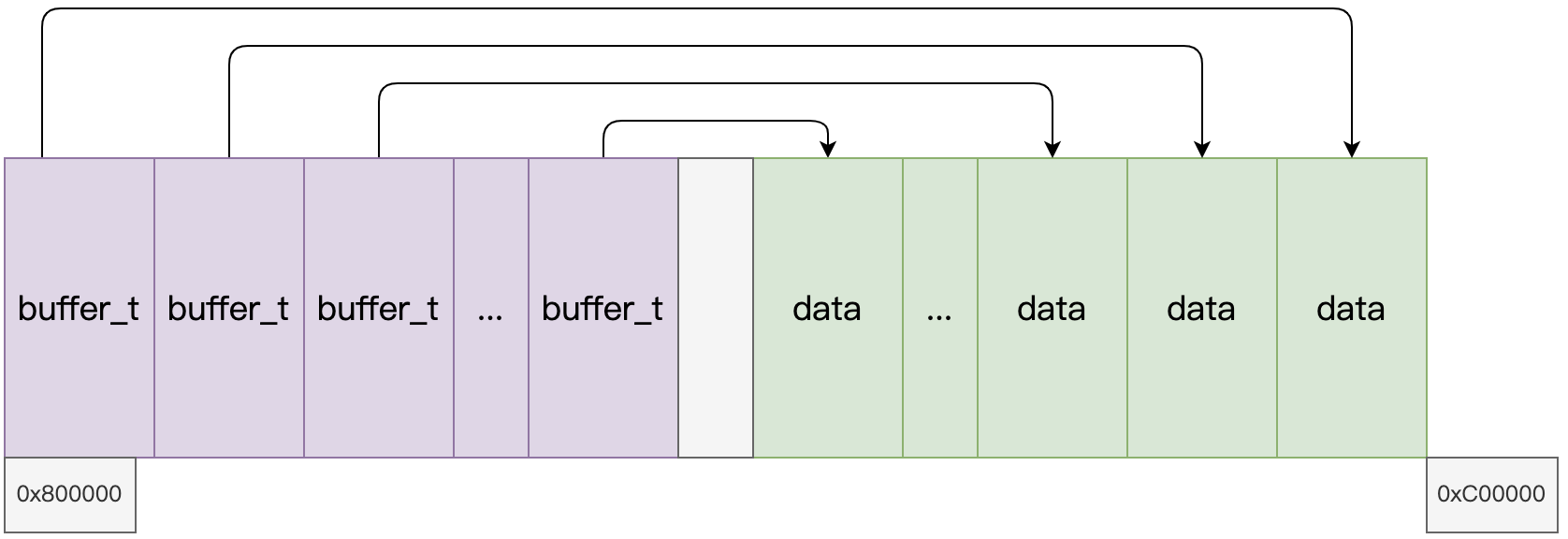
高速缓冲的布局是有buffer_t结构,指向一块儿数据区,如下所示:
 这样内核的内存就需要进行调整,由原来的8M改为16M, 因此这里会对内核内存的代码,映射做一些修改,页表由原来的2个改为4个,应该多了8M。
这样内核的内存就需要进行调整,由原来的8M改为16M, 因此这里会对内核内存的代码,映射做一些修改,页表由原来的2个改为4个,应该多了8M。
以下为高速缓冲的实现,
static buffer_t *get_new_buffer() // 直接初始化过慢,按需取用
{
buffer_t *bf = NULL;
if ((u32)buffer_ptr + sizeof(buffer_t) < (u32)buffer_data) // 如果指针的位置小于data的位置,我们就认为还是有内存的
{
bf = buffer_ptr;
bf->data = buffer_data;
bf->dev = EOF;
bf->block = 0;
bf->count = 0;
bf->dirty = false;
bf->valid = false;
lock_init(&bf->lock);
buffer_count++; // buffer数量加1
buffer_ptr++; // 指针向前移动
buffer_data -= BLOCK_SIZE; // data向后移动
LOGK("buffer count %d\n", buffer_count);
}
return bf;
}
static buffer_t *get_free_buffer() // 获得空闲的 buffer
{
buffer_t *bf = NULL;
while (true)
{
bf = get_new_buffer(); // 如果内存够,直接获得缓存
if (bf)
{
return bf;
}
if (!list_empty(&free_list)) // 否则,从空闲列表中取得
{
bf = element_entry(buffer_t, rnode, list_popback(&free_list)); // 取最远未访问过的块
hash_remove(bf);
bf->valid = false;
return bf;
}
task_block(running_task(), &wait_list, TASK_BLOCKED); // 等待某个缓冲释放
}
}
buffer_t *getblk(dev_t dev, idx_t block) // 获得设备 dev,第 block 对应的缓冲
{
buffer_t *bf = get_from_hash_table(dev, block); // 先尝试从hash表获取,如果已有缓冲直接返回
if (bf)
return bf;
bf = get_free_buffer(); // 如果没有缓冲,则获取一个新的buffer
assert(bf->count == 0);
assert(bf->dirty == 0);
bf->count = 1;
bf->dev = dev;
bf->block = block;
hash_locate(bf); // 放到hash表
return bf;
}
buffer_t *bread(dev_t dev, idx_t block) // 读取 dev 的 block 块
{
buffer_t *bf = getblk(dev, block); // 获取缓冲
assert(bf != NULL);
if (bf->valid) // 如果缓冲有效直接返回
{
bf->count++;
return bf;
}
// 如果缓冲无效做块设备请求,从硬盘读取到buffer中
device_request(bf->dev, bf->data, BLOCK_SECS, bf->block * BLOCK_SECS, 0, REQ_READ);
bf->dirty = false;
bf->valid = true;
return bf;
}
void bwrite(buffer_t *bf) // 写缓冲
{
assert(bf);
if (!bf->dirty) // 如果现在不是脏块直接返回,是的话写会磁盘
return;
device_request(bf->dev, bf->data, BLOCK_SECS, bf->block * BLOCK_SECS, 0, REQ_WRITE);
bf->dirty = false;
bf->valid = true;
}
void brelse(buffer_t *bf) // 释放缓冲
{
if (!bf)
return;
bf->count--; // 引用计数减去1
assert(bf->count >= 0);
if (!bf->count) // 如果引用计数为0,那说明无人使用,可以做空闲处理
{
if (bf->rnode.next) // 检查 bf->rnode 是否已经在某个链表上, 避免对未链接节点调用 list_remove
{
list_remove(&bf->rnode); // 把该节点从链表中移除
}
list_push(&free_list, &bf->rnode); // 将释放的缓冲加入到空闲链表
}
if (bf->dirty)
{
bwrite(bf); // todo need write?
}
if (!list_empty(&wait_list)) // 检查是否有任务在 wait_list 上等待(通常是等待空闲 buffer 的任务队列)
{
task_t *task = element_entry(task_t, node, list_popback(&wait_list)); // 将该任务从阻塞状态唤醒/置为可运行
task_unblock(task);
}
}
void buffer_init()
{
LOGK("buffer_t size is %d\n", sizeof(buffer_t));
list_init(&free_list); // 初始化空闲链表
list_init(&wait_list); // 初始化等待进程链表
// 初始化哈希表
for (size_t i = 0; i < HASH_COUNT; i++)
{
list_init(&hash_table[i]);
}
}
如上为高速缓冲的实现,依然可以在0号系统调用进行测试。通过高速缓冲,可以提高磁盘的读写效率。最后我们梳理一下缓冲的过程:
- 需求读取磁盘的某块,首先去hash表中查找我们要读取的块是否存在, 如果找到就直接使用。
- 如果没有找到就去缓冲内存中查看是否还有空闲的内存空间,有的话就申请一块儿。
- 如果缓冲内存耗尽就去空闲链表中找一个块儿。(被释放的缓存会加入到空闲链表)
- 如果一块被释放过了,再次被使用,那它在空闲链表和hash表中都有,就直接返回不需要再读硬盘了。
「真诚赞赏,手留余香」
 WangFuJie Blog
WangFuJie Blog
真诚赞赏,手留余香
使用微信扫描二维码完成支付
