一、当前内存布局
声霸卡驱动和软盘驱动都是使用DMA的方式进行内存和设备间进行数据传输,DMA访问需要直接访问物理内存。因此我们重新调整内存布局如下:
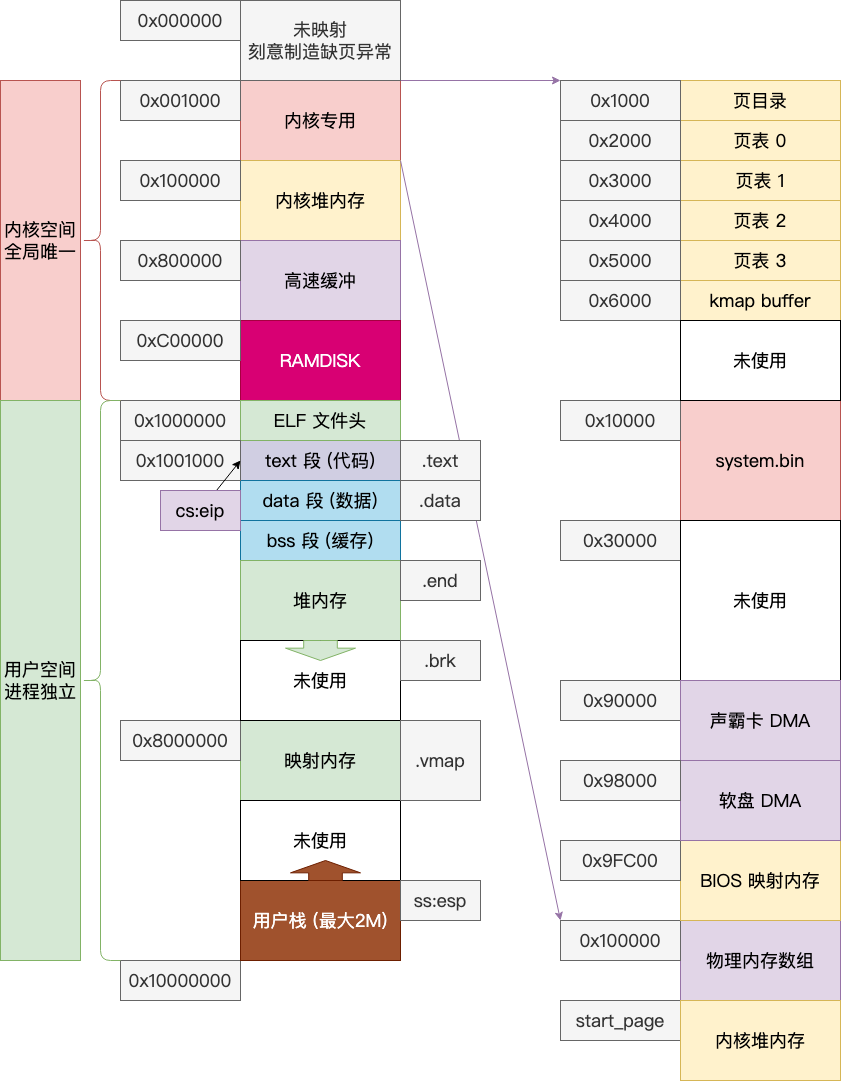
二、软盘驱动
软盘控制器(FDC Floppy Disk Controller)是一种传统设备,用于在桌面 x86 系统上控制内部 3.5/5.25 英寸软盘驱动器设备。在实模式下,使用 BIOS 功能 INT 13H AH=2(读) 或 AH=3(写) 访问软驱。在实模式中访问软盘与访问硬盘(使用 CHS 模式)是相同的。
软驱专用于 CHS 寻址,然而,在 LBA(Logic Block Address 逻辑块寻址) 中寻址更符合逻辑,因为第一个扇区位于 0(像一个数组)。因此需要将CHS通过公式转换为LBA。软盘通常使用 ISA DMA 来进行数据传输, 软盘硬连接到 DMA 通道 2。
typedef struct fdresult_t // 软盘结果
{
u8 st0;
u8 st1;
u8 st2;
u8 st3;
u8 track;
u8 head;
u8 sector;
u8 size;
} fdresult_t;
typedef struct floppy_t
{
task_t *waiter; // 等待进程
timer_t *timer; // 定时器
lock_t lock; // 锁
char name[8];
int type; // 软盘类型
u8 dor; // dor registers
u8 *buf; // DMA 地址 (其实是一样的)
union
{
u8 tracks; // 磁道数
u8 cylinders; // 柱面数
};
u8 heads; // 磁头数
u8 sectors; // 每磁道扇区数
u8 gap3; // GAP3 长度
u8 drive; // 磁盘序号
u8 st0; //
u8 track; // 当前磁道
u8 motor; // 马达状态
u8 changed; // 磁盘发生改变
union
{
u8 st[RESULT_NR];
fdresult_t result;
};
} floppy_t;
static floppy_t floppy; // 为简单起见,系统暂时只支持一个 1.44M 软盘
static err_t fd_write(floppy_t *fd, void *buf, u8 count, idx_t lba)
{
assert(count + lba < (u32)fd->tracks * fd->heads * fd->sectors);
lock_acquire(&fd->lock); // 申请锁
fd_motor_on(fd); // 开启马达
u8 left = count;
int ret;
while (left)
{
if ((ret = fd_transfer(fd, FD_WRITE, buf, count, lba)) < EOK) // 讲LBA转换为CHS
break;
left -= ret;
lba += ret;
}
fd_motor_off(fd); // 关闭马达
lock_release(&fd->lock);
return ret;
}
如上所示,我们只展示了软盘读的实现。软盘每次进行读写前都要打开马达,完成后再关闭马达。并且当一个磁盘的读写操作发生错误,或某些其它情况导致一个驱动器的马达没有被关闭。此时我们也需要让系统在一定时间之后自动将其关闭。 因此软盘的读写性能极差且不稳定。
在识别软盘后,它可以和普通硬盘一样进行格式化和挂载,并进行读写操作。
三、PCI总线
PCI总线也属于用于连接外设的I/O总线。在传统 PC 架构(北桥 / 南桥结构)中,数据通路如下:
[CPU] ── 系统总线 ── [北桥] ── 内存总线 ── [内存]
│
└── I/O 总线(PCI、ISA等) ── [南桥] ── 外设
“PCI 编程”是通过一套标准寄存器与配置空间机制与 PCI 设备通信的。每个 PCI 设备都有一个 256 字节的配置空间。前 64 字节是标准定义的通用头部:如厂商id、设备id。通过标准的配置空间机制读取设备信息、分配资源、映射寄存器,然后由驱动程序与设备通信。
总之,PCI总线我们这里了解即可,不需要太深入的去研究。
四、IDE 硬盘 UDMA
我们当前使用的硬盘读写是PIO模式,它需要CPU进行端口操作,效率是比较低下的。我们这里对机制读写机制进行下复盘和比对:
4.1、IDE 硬盘机制
- read/write buf 用户缓冲
- bread/bwrite buffer_t 查找内核高速缓冲
- 如果没有则进行磁盘访问 ide_pio_read/write 比较耗时
- buf 和 buffer_t 之间有一次拷贝内存 memcpy
4.2、ISA DMA 软盘机制
- read/write buf 用户缓冲
- bread/bwrite buffer_t 查找内核高速缓冲
- 如果没有则进行磁盘访问 isa_dma,比较低效
- buf 和 buffer_t 之间有一次拷贝内存 memcpy
- 由于 dma_buf 的限制,buffer_t 和 dma_buf 之间有一次内存拷贝 memcpy
4.3、UDMA
UDMA 是 Ultra Direct Memory Access 的缩写,它利用了PCI总线的DMA。性能高于PIO。过程大致如下:
- 在系统内存中准备一个 PRDT。
- 发送物理 PRDT 地址到总线主 PRDT 寄存器。
- 通过设置总线主命令寄存器的读/写位来设置数据传输的方向。
- 清除总线主状态寄存器中的错误和中断位。
- 选择驱动器(硬盘)。
- 将 LBA 和扇区计数发送到各自的端口。
- 向 ATA 控制器发送 DMA 传输命令。
- 在总线主命令寄存器上设置启动/停止位。
- 当中断到达时(传输完成后),通过重置启动/停止位来响应。
- 读取控制器和驱动器状态,以确定传输是否成功完成。
五、总结
在这篇文章中,我们只是粗略的介绍了软盘驱动、PCI总线和IDE的DMA,没有进行详细的描述实现过程,笔者这里是认为这些比较涉及硬件操作(即对ISA总线和PCI总线的理解),且属于对系统的优化, 并且实现很复杂。具体实现可自行阅读源代码。
「真诚赞赏,手留余香」
 WangFuJie Blog
WangFuJie Blog
真诚赞赏,手留余香
使用微信扫描二维码完成支付
