一、字符编码发展史
计算机是基于电工作只能识别二进制,人类的字符如果让计算机读懂,需要翻译成二进制。因此就需要在人类字符和二进制之间建立一种映射关系,这种关系就是字符编码表。
1.1、ASCII编码
ASCII编码(美国信息互换标准代码)是历史上第一个字符编码表。由于计算机产生于美国,当时他们并未考虑其他国家的字符,因此只把英文符、数字、控制字符和键盘上的特殊字符存入了ASCII编码表。ASCII共记录了128个字符,采用了8个二进制位进行编码。ASCII码表。8位可以存储256个字符,当时是考虑到后续字符扩展预留了空间,后来将拉丁文也扩展到了ASCII码表中了,也就是latin1字符集。
1.2、中文字符编码标准
随着计算机的普及,当中国用上计算机时,发现不支持中文,因为ASCII中并不支持中文字符。于是中国指定自己的标准编码表。中国共发布了三个中文编码标准,分别是GB2312、GBK、GB18030。
1.2.1、GB2312编码
GB2312 全称:GB 2312-1980《信息交换用汉字编码字符集·基本集》,1980年由中国国家标准总局发布。包含 6763 个汉字 + 682 个非汉字字符(符号、拉丁字母、日文假名等),采用双字节(16位)编码,兼容 ASCII,存储英文仍然使用1个字节,所有汉字和非 ASCII 符号使用 2 字节。
1.2.2、GBK编码
全称:GBK 1.0(GBK = “GuoBiao Kuozhan”,即“国标扩展”)。于1995年发布,由微软主导并成为国家标准。它是GB2312的扩展,向下兼容GB2312,包含 GB2312 的所有字符,并扩展到 21003 个汉字(包括繁体字和更多生僻字)。仍然使用两个字节进行编码,GBK也是国内Windows系统的默认编码。
1.2.3、GB18030编码
全称:GB 18030-2005《信息技术 中文编码字符集》,于2000年首次发布,2005年修订成为强制性国家标准。全面覆盖 Unicode,支持 70244 个汉字(包括所有 CJK 统一汉字)。向下兼容 GB2312 和 GBK。采用多字节可变长编码,GBK 范围内的字符仍然是 2 字节,超出 GBK 的字符采用 4 字节编码(以支持 Unicode 全集)
1.2、Unicode编码
各国家使用计算机也需要支持各自的字符,例如日本制定了Shift_JIS编码表,韩国制定了Euc-kr编码表。这样各自虽然相安无事,但是存在一个问题是,中国开发的软件拿到其他国家的电脑上就不能使用,开发国际软件就会存在极大的困难。
基于此问题ISO组织就推出了Unicode编码标准,又称万国码。Unicode是一种字符集标准,它为每个字符分配唯一的代码点。
1.2.1、Unicode编码实现
Unicode只是一个编码标准,有多种实现。Unicode最初使用双字节实现,即UCS-2编码。后来发现65536个字符远远不够,又推出了UTF-16编码。UTF-16仍然使用 2 字节为基本单元,但引入代理对。UTF-16向下兼容UCS-2,信扩展的字符使用4个字节表示。
1.2.2、历史遗留问题
现在的计算机在内存里的存储统一都是Unicode编码(不同的计算机使用的实现不完全一样,例如windows使用UTF-16, linux/macos使用UTF-8)。这样就存在一个问题,许多历史的文件以各种各样的编码存储在硬盘中,这些老文件也需要能正常显示。例如一个gbk文件读入内存,需要先转换为内存使用的Unicode编码。假设我们使用的windows系统,从硬盘读取一个gbk文件,文本编辑器会首先识别文件的编码为gbk,然后将gbk序列对应到Uncode的码点,再将码点转换为UTF-16编码,就可以正常显示出俩了。总结就是:Unicode码点充当了编码转换的媒介。
1.2.3、UTF-8编码
我们知道Unicode编码通过两个字节编码,这样存在一个问题,如果一个纯英文的文本也使用Unicode,本来ASCII一个字节就可以存储,现在缺需要两个字节。这样不仅浪费了磁盘空间,读写文件也会造成严重的I/O问题。
基于此问题,Unicode实现又推出了UTF-8编码。它把英文字符对应的二进制数使用一个字节表示,中文字符对应的二进制数使用三个字节表示。这样就解决了存储英文浪费空间的问题。
二、计算机的乱码问题
我们在windows系统中演示集中产生乱码的情况,windows在国内的系统默认编码是GBK,通用微软默认韩文的windows系统默认编码是EUC-KR。虽然各种语言的编码不一样,微软把他们统一名为为ANSI,在windows系统中ANSI就代表系统的默认编码,中文为GBK。
2.1、数据存乱了
我们使用notepadd++新建一个文件,分别写入两行数据,分别是中文字符和日文字符。
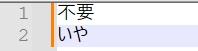 中文和日文都可以正常显示,这是因为现在字符保存在内存中,内存中的编码是Unicode。这时候我们再新建一个空文件,设置字符编码为Shift_jis,同样输入这两行字符,点击保存。发现保存了之后仍然是正常显示,这是因为页面显示的仍是内存中的数据。但是保存之后到硬盘上的已经是Shitf_jis编码了。我们再打开文件,发现中文乱码了。
中文和日文都可以正常显示,这是因为现在字符保存在内存中,内存中的编码是Unicode。这时候我们再新建一个空文件,设置字符编码为Shift_jis,同样输入这两行字符,点击保存。发现保存了之后仍然是正常显示,这是因为页面显示的仍是内存中的数据。但是保存之后到硬盘上的已经是Shitf_jis编码了。我们再打开文件,发现中文乱码了。
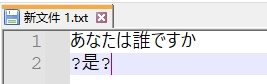 这里解释下原因,在存储时,把内存中文Unicode的二进制转换为Shift_jis的二进制,但是中文在Shift_jis里并没有对应的编码,于是notepad++进行了乱存。重新打开,noetepad++识别第一行为日文,自动认为编码是Shift_jis, 于是日文正常显示,但是中文出现了乱码。
这里解释下原因,在存储时,把内存中文Unicode的二进制转换为Shift_jis的二进制,但是中文在Shift_jis里并没有对应的编码,于是notepad++进行了乱存。重新打开,noetepad++识别第一行为日文,自动认为编码是Shift_jis, 于是日文正常显示,但是中文出现了乱码。
可以看到中文的第二个字可以正常显示,但是另外两个被替换成了问号。这是因为这两个汉字法在 Shift_JIS 中找到对应的编码,些字符会被替换为 问号(?) 或 其他占位符(如 □、‾),具体表现取决于编辑器或转换工具的策略。
2.2、数据取乱了
现在我们使用gb2312重新创建一个新文件,写入中文字符并保存到硬盘。我们重新打开会发现是正常显示的。notepad++自动识别字符编码为ANSI。然后把文件编码改为Shift_JIS
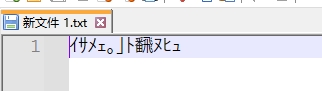 发现数据乱码了。这是因为存储的数据是GB2312的编码格式,但是读取时候是按照Shift_JIS将它映射为Unicode数据的,因此出现了乱码。但是数据取乱了问题不大,因为存储的数据并没有乱。我们读取它的时候使用存储时的编码格式就可以了。
发现数据乱码了。这是因为存储的数据是GB2312的编码格式,但是读取时候是按照Shift_JIS将它映射为Unicode数据的,因此出现了乱码。但是数据取乱了问题不大,因为存储的数据并没有乱。我们读取它的时候使用存储时的编码格式就可以了。
三、总结
为了避免出现乱码,我们应尽量统一使用UTF-8编码,这也是目前最主流的编码方式。
「真诚赞赏,手留余香」
 WangFuJie Blog
WangFuJie Blog
真诚赞赏,手留余香
使用微信扫描二维码完成支付
