一、跳表概述
跳表(skiplist)是一种随机化的数据, 以有序的方式在层次化的链表中保存元素, 效率和平衡树媲美 —— 查找、删除、添加等操作都可以在对数期望时间下完成。以下是个典型的跳跃表例子:
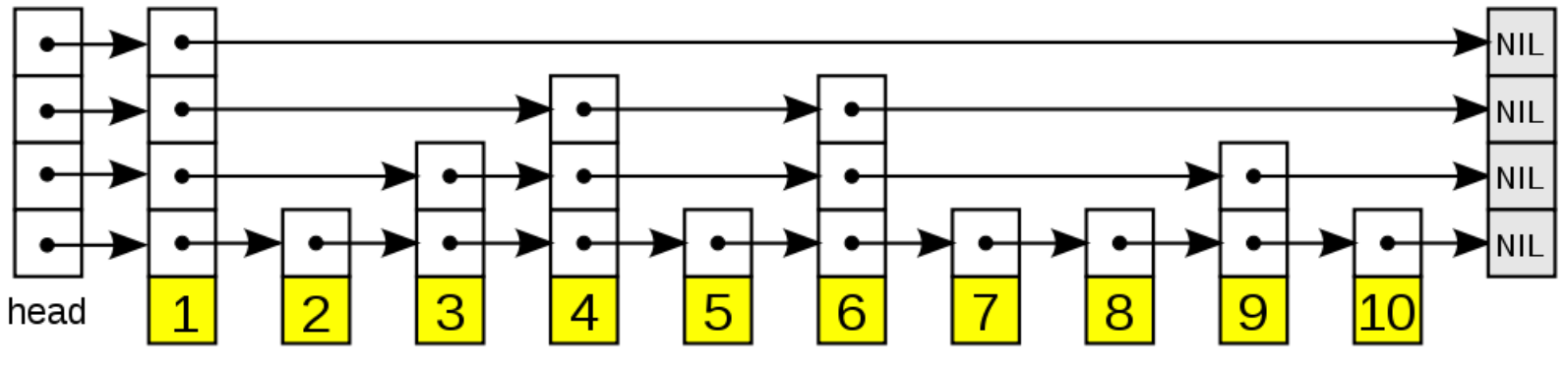
- 表头(head):负责维护跳跃表的节点指针。
- 跳跃表节点:保存着元素值,以及多个层。
- 层:保存着指向其他元素的指针。高层的指针越过的元素数量大于等于低层的指针,为了提高查找的效率,程序总是从高层先开始访问,然后随着元素值范围的缩小,慢慢降低层次。
- 表尾:全部由 NULL 组成,表示跳跃表的末尾。
二、跳表的实现
跳表的结构定义在 redis.h 文件中,具体实现在t_zset.c 文件中。zskiplist定义了跳表的结构,zskiplistNode定义了跳表的节点。
typedef struct zskiplistNode {
sds ele; // 元素
double score; // 分值
struct zskiplistNode *backward; // 后退指针
struct zskiplistLevel { // 节点的level数组,保存每层上的前向指针和跨度
struct zskiplistNode *forward; // 前进指针
unsigned long span; // 这个层跨越的节点数量
} level[];
} zskiplistNode;
typedef struct zskiplist {
struct zskiplistNode *header, *tail; // 头节点,尾节点
unsigned long length; // 节点数量
int level; // 目前表内节点的最大层数
size_t alloc_size; // 记录跳表申请的内存大小
} zskiplist;
跳表在 Redis 中的唯一核心用途是有序集合的底层实现,从代码的位置也可以看到,在t_set中实现。因为 Sorted Set 中既要保存元素,也要保存元素的权重,所以对应到跳表结点的结构定义中,就对应了 sds 类型的变量 ele,以及 double 类型的变量 score。此外,为了便于从跳表的尾结点进行倒序查找,每个跳表结点中还保存了一个后向指针(*backward),指向该结点的前一个结点。
然后,因为跳表是一个多层的有序链表,每一层也是由多个结点通过指针连接起来的。因此在跳表结点的结构定义中,还包含了一个 zskiplistLevel 结构体类型的 level 数组。
level 数组中的每一个元素对应了一个 zskiplistLevel 结构体,也对应了跳表的一层。而 zskiplistLevel 结构体定义了一个指向下一结点的前向指针(forward),这就使得结点可以在某一层上和后续结点连接起来。同时,zskiplistLevel 结构体中还定义了,这是用来记录结点在某一层上的跨度forward指针和该指针指向的结点之间,跨越了 level0 上的几个结点。下图展示一个3层的跳表:
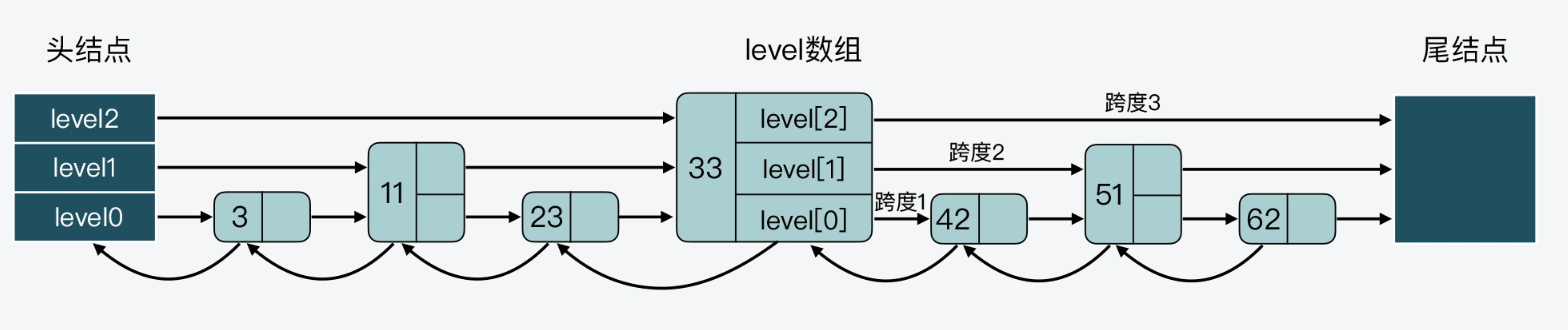
三、跳表的基本操作
我们这里结合代码来看一下跳表的一些基本操作,包括跳表的创建、增加数据、创建节点等功能。
3.1、跳表的创建
首先来看下跳表是如何创建的,实现如下:
zskiplist *zslCreate(void) {
int j;
zskiplist *zsl;
size_t zsl_size; // 用于记录实际可使用的内存,申请的内存可能比sizeof(*zsl)略大
zsl = zmalloc_usable(sizeof(*zsl), &zsl_size); // 申请内存
zsl->level = 1; // 初始化层数为1
zsl->length = 0; // 初始化节点数为0
zsl->alloc_size = zsl_size;
zsl->header = zslCreateNode(zsl,ZSKIPLIST_MAXLEVEL,0,NULL); // 创建头结点,头节点默认就有32层,即支持的最大层数
for (j = 0; j < ZSKIPLIST_MAXLEVEL; j++) { // 初始化头结点的每层下一节点都是NULL,跨度为0
zsl->header->level[j].forward = NULL;
zsl->header->level[j].span = 0;
}
zsl->header->backward = NULL; // 设置头节点的前置节点为NULL,backward 指针(物理指针)只有第 0 层有
zsl->tail = NULL; // 设置尾节点为NULL
return zsl;
}
以上是新建一个跳表的功能,可以看到跳表最大支持32层,由宏常量ZSKIPLIST_MAXLEVEL指定。一个新的跳表通过zslCreateNode函数创建头节点,如上所示头结点具有32层,因为每一次都需要从头节点开始。头结点的每层指向的下一个节点都是NULL且跨度为0。同时设置尾节点为NULL。接下来我们看下跳表节点是如何创建的
zskiplistNode *zslCreateNode(zskiplist *zsl, int level, double score, sds ele) { // 创建一个跳表节点,需要指定层数,分数和字符串
size_t usable;
zskiplistNode *zn =
zmalloc_usable(sizeof(*zn)+level*sizeof(struct zskiplistLevel), &usable); // 申请内存
zn->score = score;
zn->ele = ele;
zsl->alloc_size += usable;
if (ele) zsl->alloc_size += sdsAllocSize(ele); // 如果存储了元素,那跳表的内存大小同样也记录元素的大小
return zn;
}
结合这个函数,我们能看到头结点在创建时,指定了元素为NULL,分数为0。
3.2、插入节点
在插入一个新节点时,这个节点应该应该按照分数的顺序插入到指定位置,但是它的层数应该如何决定呢,我们还是从代码中找答案,插入节点的实现还是比较复杂的,我们分部分解释。
第一部分,查找插入位置
zskiplistNode *zslInsert(zskiplist *zsl, double score, sds ele) { // 给跳表插入一个元素
zskiplistNode *update[ZSKIPLIST_MAXLEVEL], *x; // 每一层“插入位置的前驱节点”, x用于记录当前遍历指针
unsigned long rank[ZSKIPLIST_MAXLEVEL]; // 记录从 header 到当前节点的排名(跨过的元素数量)
int i, level;
x = zsl->header; // 从头节点开始
for (i = zsl->level-1; i >= 0; i--) { // 从跳表当前最高层开始遍历,查找插入位置
rank[i] = i == (zsl->level-1) ? 0 : rank[i+1]; // 初始化rank,最高层为0,其他层继承上一层
while (x->level[i].forward &&
(x->level[i].forward->score < score ||
(x->level[i].forward->score == score &&
sdscmp(x->level[i].forward->ele,ele) < 0))) // 向右走,直到找到插入点, 先按 score,score 相同按 ele(字典序)
{
rank[i] += x->level[i].span; // rank 增加(跨过的节点数)
x = x->level[i].forward; // x 向前移动
}
update[i] = x; // 记录这一层:插入位置的前驱节点
}
.....
在执行完这段代码后,每一层都找到了:插入位置、前驱节点 update[i] 和 当前排名 rank[i]. 我们结合一个上文中的图来解释,假设要插入一个45。
- 先遍历第二层,从头开始,判断它应该插入到33之后,从头结点开始遍历,当到33时,满足条件,记录头结点到33的跨度为4。继续向后遍历,到尾节点不满足条件,因此记录rank[2] = 4、update[2] 指向33 ,x当前节点也到了33.
- 遍历第一层,继承上一层跨度4,从33继续在第二层向后遍历到节点51,不满足条件,因此记录rank[1] = 4、 update[1] 指向33 ,x当前节点继续在33.
- 遍历第0层,继承上一层跨度4,从33继续遍历到42满足条件,rank增加1。到了51不满足。因此记录rank[0] = 5、 update[1] 指向42 ,x当前节点移动到42.
第二部分:计算新节点的层数
如上:redis采用随机函数决定一个新节点共有几层,初始化为1层,然后随机一个数字判断这个数字小于0.25的概率,如果满足就增加一层。继续判断再满足就再增加一层。因此表明每增加一层的概率不超过 25%。实现如下:
level = zslRandomLevel(); // 随机生成新节点的层数(概率 1/4 递减)
if (level > zsl->level) {
for (i = zsl->level; i < level; i++) {
rank[i] = 0;
update[i] = zsl->header;
update[i]->level[i].span = zsl->length;
}
zsl->level = level;
}
int zslRandomLevel(void) { // 决定的是“某一个节点”的层数, 1层的概率是75%,层数越多概率越低
static const int threshold = ZSKIPLIST_P*RAND_MAX; // 定义增加层数的概率。
int level = 1; // 初始化层位1
while (random() < threshold) // 如果生成随机数小于 0.25*整数最大值,这个条件成功的概率是0.25。那就增加一层
level += 1;
return (level<ZSKIPLIST_MAXLEVEL) ? level : ZSKIPLIST_MAXLEVEL; // 如果level小于最大支持层数,就返回level,否则返回最大层数。
}
从代码可以看出,如果新节点的层数超过了当前的最高层,就需要设置新的最高层,我们还是以刚才的例如,假设新插入的45共有4层,那么目前的变量如下:rank[3] = 0 update[3] = header , 第三层的头节点span就是所有节点的个数,因为目前第三层还没有数据,头节点下一个指针直接指向尾节点。
第三部分:创建新节点,并执行插入
指向插入的代码如下:
x = zslCreateNode(zsl,level,score,ele); // 创建一个新节点,x指向这个新节点
for (i = 0; i < level; i++) { // 对新节点的层数进行遍历
x->level[i].forward = update[i]->level[i].forward; // 新插入节点的后继节点,指向插入位置前驱节点的下一个节点
update[i]->level[i].forward = x; // 插入位置的前驱节点的后继节点指向这个新节点
x->level[i].span = update[i]->level[i].span - (rank[0] - rank[i]); // 新节点到下一节点的跨度为 前驱节点的跨度 - (从前驱到插入位置之间,底层跨了的节点数)
update[i]->level[i].span = (rank[0] - rank[i]) + 1; // 前驱节点的跨度更新,(从前驱到插入位置之间,底层跨了的节点数)+ 1
}
for (i = level; i < zsl->level; i++) { // 遍历新节点以上每一层,将新节点的前驱节点的跨度+1,因为添加了一个节点,对应的跨度就要+1
update[i]->level[i].span++;
}
x->backward = (update[0] == zsl->header) ? NULL : update[0]; // 设置新节点的在第0层的前驱指针
if (x->level[0].forward) // 如果x有后继节点,那说明插入不是尾部
x->level[0].forward->backward = x; // 新节点的后继节点的前驱指针指向这个节点。
else
zsl->tail = x; // 把跳表的“尾指针”更新为新节点 x
zsl->length++; // 跳表的元素总数+1
return x; // 返回新插入的节点
如上,为跳表插入新节点的整个流程,我们可以看到还是非常复杂难以理解的。针对不同的情况走的代码分支也不完全相同,这里可以根据笔者的图来理解每行代码为什么这么写。
3.2、跳表查询
当查询一个结点时,跳表会先从头结点的最高层开始,查找下一个结点。而由于跳表结点同时保存了元素和权重,所以跳表在比较结点时,相应地有两个判断条件:
- 当查找到的结点保存的元素权重,比要查找的权重小时,跳表就会继续访问该层上的下一个结点。
- 当查找到的结点保存的元素权重,等于要查找的权重时,跳表会再检查该结点保存的 SDS 类型数据,是否比要查找的 SDS 数据小。如果结点数据小于要查找的数据时,跳表仍然会继续访问该层上的下一个结点。
但是,当上述两个条件都不满足时,跳表就会用到当前查找到的结点的 level 数组了。跳表会使用当前结点 level 数组里的下一层指针,然后沿着下一层指针继续查找,这就相当于跳到了下一层接着查找。我们以 zslGetRank 函数为例:
unsigned long zslGetRank(zskiplist *zsl, double score, sds ele) {
zskiplistNode *x;
unsigned long rank = 0;
int i;
x = zsl->header; // //获取跳表的表头
for (i = zsl->level-1; i >= 0; i--) { // 从最大层数开始逐一遍历
while (x->level[i].forward && // 如果下一个节点score 更小 或者 score 相等 且 ele 更小或相等 那就继续走
(x->level[i].forward->score < score ||
(x->level[i].forward->score == score &&
sdscmp(x->level[i].forward->ele,ele) <= 0))) {
rank += x->level[i].span; // 累计跨越了多少个底层节点
x = x->level[i].forward;
}
if (x->ele && x->score == score && sdscmp(x->ele,ele) == 0) { // 找到了就返回元素的位置
return rank;
}
}
return 0; // 没找到的情况 返回0,
}
它的作用是返回指向元素在跳表中的排名,这个遍历的过程还是比较重要的,在跳表中进行查找、插入、更新或删除操作时,都需要用到查询的功能。
3.3、操作总结
这本章节中,我们只介绍了跳表的创建、插入节点、和其中一个查询操作。 除此之外,它还具有很多的API,如删除节点,按照范围删除,范围查询。但是整体逻辑都是类似的,我们这里不对每个函数的实现进行逐行解析。
四、跳表的应用
跳跃表在 Redis 的唯一作用, 就是实现有序集数据类型。跳跃表将指向有序集的 score 值和 member 域的指针作为元素, 并以 score 值为索引, 对有序集元素进行排序。zset同时使用了 跳表和哈希表这两种所有结构,这也就解释了为什么zset可以同时进行一下两种操作:
- ZRANGEBYSCORE:按照元素权重返回一个范围内的元素。 复杂度 O(logN)+M
- ZSCORE:返回某个元素的权重值。 复杂度 O(logN)+M 和 O(1) 呢
在本篇文章中,我们中点学习跳表这种数据结构,等后续介绍数据类型时,我们再分享跳表在有序集合中时如何使用的。
「真诚赞赏,手留余香」
 WangFuJie Blog
WangFuJie Blog
真诚赞赏,手留余香
使用微信扫描二维码完成支付
