一、压缩链表概述
Ziplist 是由一系列特殊编码的内存块构成的列表, 一个 ziplist 可以包含多个节点(entry), 每个节点可以保存一个长度受限的字符数组(不以 \0 结尾的 char 数组)或者整数, 包括:
- 字符数组
- 长度小于等于 63 (2**6−1)字节的字符数组
- 长度小于等于 16383 (2**14−1) 字节的字符数组
- 长度小于等于 4294967295 (2**32−1)字节的字符数组
- 整数
- 4 位长,介于 0 至 12 之间的无符号整数
- 1 字节长,有符号整数
- 3 字节长,有符号整数
- int16_t 类型整数
- int32_t 类型整数
- int64_t 类型整数
压缩链表每个节点支持以上类型,这些类型通过一个字节来进行编码,代码位于 ziplist.c 中。如下:
#define ZIP_STR_MASK 0xc0 // 最高2位(7、8位)用于标识字符串 1100 0000, 字符串不会以11作为最高位,如果前两位是11代表是数字
#define ZIP_INT_MASK 0x30 // 5位和6位标识整数 0011 0000 最高两位必须是11
#define ZIP_STR_06B (0 << 6) // 第一个字节后6位:表示字符串长度(0~63)
#define ZIP_STR_14B (1 << 6) // 14位存储字符串长度 0100 0000
#define ZIP_STR_32B (2 << 6) // 32位存储字符串长度 1000 0000
#define ZIP_INT_16B (0xc0 | 0<<4) // 2字节整数,。 1100 0000
#define ZIP_INT_32B (0xc0 | 1<<4) // 4字节整数 1101 0000
#define ZIP_INT_64B (0xc0 | 2<<4) // 8字节整数 1110 0000
#define ZIP_INT_24B (0xc0 | 3<<4) // 3字节整数
#define ZIP_INT_8B 0xfe // 1字节整数
#define ZIP_INT_IMM_MASK 0x0f // 四位小整数。最小是0,最大12 0001 表示整数0。也叫立即数
#define ZIP_INT_IMM_MIN 0xf1 // 11110001 立即数的最小值表示法
#define ZIP_INT_IMM_MAX 0xfd // 11111101 立即数的最大值表示法
通过压缩列表的编码风格可以看到,redis对内存的使用非常紧凑。压缩链表可以起到节省内存的效果,但是它也存在缺点,查找复杂度高和潜在的连锁更新风险。
在Redis的较高版本中,压缩链表基本已经废弃,但是源码中依然进行了保留。这里笔者认为保留原因是为了兼容性,当低版本的备份数据恢复到高版本时,可以正常进行解析。不过为了介绍Redis数据结构的演变过程,我们这里还是了解一下压缩链表。
二、压缩链表的构成
一个 ziplist 数据结构在内存中的布局,就是一块连续的内存空间。这块空间的起始部分是大小固定的 10 字节元数据,其中记录了 ziplist 的总字节数、最后一个元素的偏移量以及列表元素的数量,而这 10 字节后面的内存空间则保存了实际的列表数据。在 ziplist 的最后部分,是一个 1 字节的标识(固定为 255),用来表示 ziplist 的结束。如下图所示:
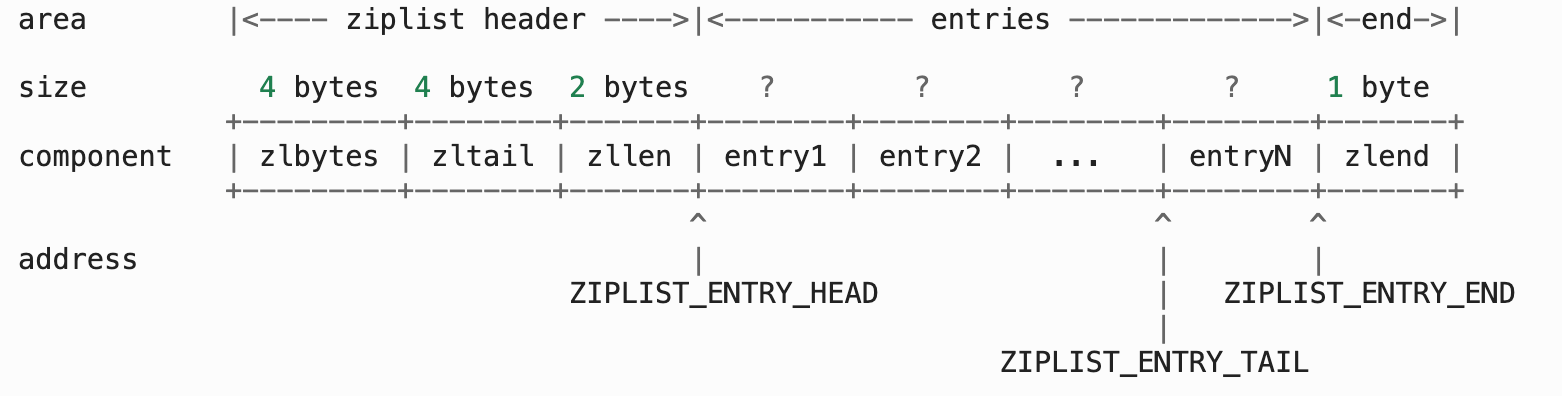
- zlbytes 4字节,用于ziplist 占用的内存字节数,对 ziplist 进行内存重分配,或者计算末端时使用。
- zltail 4字节,记录到达 ziplist 表尾节点的偏移量。 通过这个偏移量,可以在不遍历整个 ziplist 的前提下,弹出表尾节点。
- zllen 2字节,记录ziplist 中节点的数量。 当这个值小于 UINT16_MAX (65535)时,这个值就是 ziplist 中节点的数量; 当这个值等于 UINT16_MAX 时,节点的数量需要遍历整个 ziplist 才能计算得出。
- entryX ziplist 所保存的节点,各个节点的长度根据内容而定。
- zlend 1字节 固定值255 的二进制值 1111 1111 (UINT8_MAX) ,用于标记 ziplist 的末端
因为 ziplist header 部分的长度总是固定的(4 字节 + 4 字节 + 2 字节), 因此将指针移动到表头节点的复杂度为常数时间; 除此之外, 因为表尾节点的地址可以通过 zltail 计算得出, 因此将指针移动到表尾节点的复杂度也为常数时间。
三、节点的构成
一个压缩链表可以保存多个节点,每个节点可以划分为如下几部分:

3.1、pre_entry_length
pre_entry_length 记录了前一个节点的长度,通过这个值,可以进行指针计算,从而跳转到上一个节点。用指向当前节点的指 , 减去 pre_entry_length 的值, 得出的结果就是指向前一个节点的地址。根据编码方式的不同, pre_entry_length 域可能占用 1 字节或者 5 字节:
- 1 字节:如果前一节点的长度小于 254 字节,便使用一个字节保存它的值。
- 5 字节:如果前一节点的长度大于等于 254 字节,那么将第 1 个字节的值设为 254 ,然后用接下来的 4 个字节保存实际长度。
如果长度为 5 字节的 pre_entry_length, 第一个字节被设为 254 的二进制 1111 1110 , 而之后的四个字节则被设置为实际长度的二进制(多余的高位用 0 补完。
3.2、encoding 和 length
encoding 和 length 两部分一起决定了 content 部分所保存的数据的类型(以及长度)。其中, encoding 域的长度为两个 bit , 它的值可以是 00 、 01 、 10 和 11 :
- 00 、 01 和 10 表示 content 部分保存着字符数组。
- 11 表示 content 部分保存着整数
| 编码 | 编码长度 | content 部分保存的值 |
|---|---|---|
| 00bbbbbb | 1 byte | 长度小于等于 63 字节的字符数组 |
| 01bbbbbb xxxxxxxx | 2 byte | 长度小于等于 16383 字节的字符数组 |
| 10____ aaaaaaaa bbbbbbbb cccccccc dddddddd | 5 byte | 长度小于等于 4294967295 的字符数组 |
表格中的下划线 _ 表示留空,而变量 b 、 x 等则代表实际的二进制数据。为了方便阅读,多个字节之间用空格隔开。
11 开头的整数编码如下:
| 编码 | 编码长度 | content 部分保存的值 |
|---|---|---|
| 11000000 | 1 byte | int16_t 类型的整数 |
| 11010000 | 1 byte | int32_t 类型的整数 |
| 11100000 | 1 byte | int64_t 类型的整数 |
| 11110000 | 1 byte | 24 bit 有符号整数 |
| 11111110 | 1 byte | 8 bit 有符号整数 |
| 1111xxxx | 1 byte | 4 bit 无符号整数,介于 0 至 12 之间 |
这些代码的定义在上文中已经进行了展示,可以结合代码来具体理解。 length 的长度需要根据编码类型来决定,宏函数 ZIP_DECODE_LENGTH 实现了根据传入的编码类型指针和编码类型,计算该数据类型的实际长度(字符串就计算字符串长度,数字就返回字节数如1字节给len)。并且计算为存储len这个元素,需要多少的内存,保存到lensize。如整数都是1字节。立即数是0字节,字符串可能为1,2 或 5 字节。
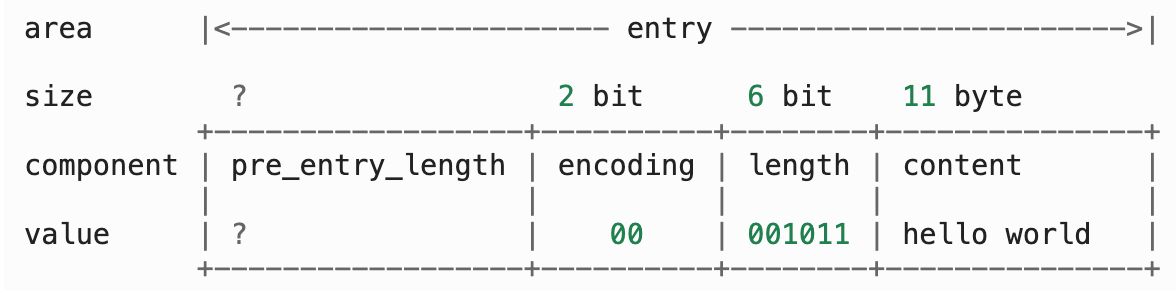
3.3 content
content 部分保存着节点的内容,类型和长度由 encoding 和 length 决定。以下是一个保存着字符数组 hello world 的节点的例子:
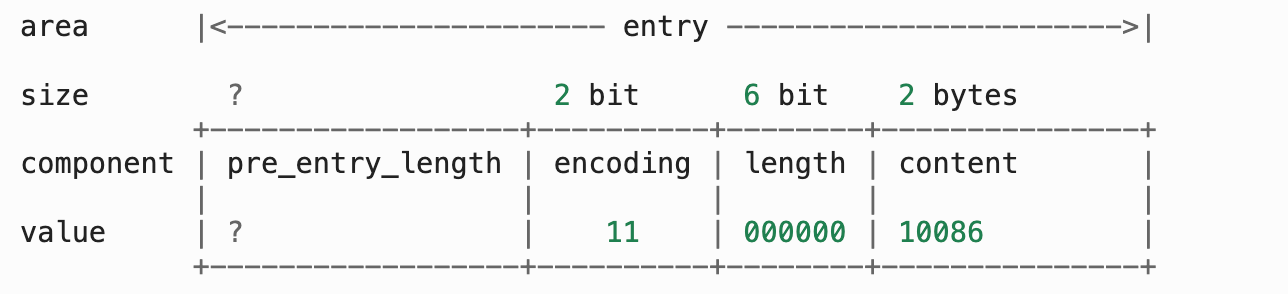
以下是另一个节点,它保存着整数 10086 :
四、压缩链表的基本操作
我们这里介绍一下ziplist的基本操作,主要介绍它的级联更新带来的性能问题,可以体验一下它逐渐被弃用的根本原因。还是先看ziplist的创建。
4.1、创建新ziplist
函数 ziplistNew 用于创建一个新的空白 ziplist。代码实现如下:
unsigned char *ziplistNew(void) { // 创建一个空的ziplist
unsigned int bytes = ZIPLIST_HEADER_SIZE+ZIPLIST_END_SIZE; // 初始申请内存大小只有头和尾, 共11字节。
unsigned char *zl = zmalloc(bytes);
ZIPLIST_BYTES(zl) = intrev32ifbe(bytes); // 把总大小赋值给zl的前4个字节,利用宏定义
ZIPLIST_TAIL_OFFSET(zl) = intrev32ifbe(ZIPLIST_HEADER_SIZE); // 把头大小赋给第二个4字节,存储最后一个元素的偏移量
ZIPLIST_LENGTH(zl) = 0; // 此时没有数据,长度存储0
zl[bytes-1] = ZIP_END;
return zl;
}
目前是一个空白的ziplist,表尾和末端处于同一地址。示意图如下:

4.2、插入一个新节点
在插入新节点时,有两种情况。一种是插入到末端和头部、一种是插入的中间。插入到末端或头部的实现函数是 ziplistPush,插入到指定位置的函数是 ziplistInsert。它们的本质都是调用了 __ziplistInsert 函数。代码如下:
// 在指针p处插入一个新数据 s, 它的长度是 slen
unsigned char *__ziplistInsert(unsigned char *zl, unsigned char *p, unsigned char *s, unsigned int slen) {
size_t curlen = intrev32ifbe(ZIPLIST_BYTES(zl)), reqlen, newlen; // 记录ziplist当前的大小,需要的长度 和 插入后新的总长度
unsigned int prevlensize, prevlen = 0;
size_t offset;
int nextdiff = 0;
unsigned char encoding = 0;
long long value = 123456789; /* 为了防止警告,我们将其初始化。使用一个容易看出的值,以防万一我们因某种原因未初始化就使用它 */
zlentry tail;
if (p[0] != ZIP_END) { // 如果指针p不指向终止符,获取到指针p的前一个元素的长度prevlen 和 prevlen的大小
ZIP_DECODE_PREVLEN(p, prevlensize, prevlen);
} else {
unsigned char *ptail = ZIPLIST_ENTRY_TAIL(zl); // 如果p指向终止符,获取最后一个元素的指针
if (ptail[0] != ZIP_END) { // 如果最后一个元素不是终止符,说明这个ziplist不为空,获取最后一个元素的总内存大小。
prevlen = zipRawEntryLengthSafe(zl, curlen, ptail);
} // 如果ziplist为空,那什么都不做的,即初始化的prevlen为0
}
if (zipTryEncoding(s,slen,&value,&encoding)) { // 如果这个新数据是纯数字组成的字符串,尝试进行编码
reqlen = zipIntSize(encoding); // 计算存储这个整数需要的空间
} else {
reqlen = slen; // 如果不能编码为整数,那这个字符串的实际长度就是需要的空间
}
reqlen += zipStorePrevEntryLength(NULL,prevlen); // 加上存储前一个元素需要的空间
reqlen += zipStoreEntryEncoding(NULL,encoding,slen); // 加上 encoding 字段需要占用的字节数
int forcelarge = 0; // 当插入位置不等于尾部时,我们需要确保下一个条目的prevlen字段能够容纳当前条目的长度
nextdiff = (p[0] != ZIP_END) ? zipPrevLenByteDiff(p,reqlen) : 0; // 如果插入位置在尾部则nextdiff=0,如果不在尾部则通过函数计算 前一个当前条目占用的内存 和 下一个条目元素prevlen字段的差值
if (nextdiff == -4 && reqlen < 4) { // 如果下一个节点的 prevlen 需要从 5 字节缩小为 1 字节, 但是新条目的总长度小于4(这里是一个阈值权衡只有当当前元素的体量 ≥ 4 时,这次结构变化才被认为“值得”)。
nextdiff = 0; // 不需要调整 next 节点大小
forcelarge = 1; // 强制 next 节点继续使用 5 字节 prevlen
} // 当前插入的 entry 太小,“不值得”为了它去收缩 next 的 prevlen(5→1) 因此直接放弃这次“节省 4 字节”的机会。
offset = p-zl; // 存储p指针的偏移量,因为重新分配可能会改变zl的地址
newlen = curlen+reqlen+nextdiff; // 新的ziplist总大小
zl = ziplistResize(zl,newlen);
p = zl+offset;
if (p[0] != ZIP_END) { // 如果p没有指向终止符
memmove(p+reqlen,p-nextdiff,curlen-offset-1+nextdiff); // 把p位置以后的元素向后移动
if (forcelarge) // 更新“新插入节点后面那个节点”的 prevlen
zipStorePrevEntryLengthLarge(p+reqlen,reqlen); // 正常规则(1 or 5 byte)
else
zipStorePrevEntryLength(p+reqlen,reqlen); // 强制 5 byte
ZIPLIST_TAIL_OFFSET(zl) =
intrev32ifbe(intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))+reqlen); // 更新 tail 偏移
assert(zipEntrySafe(zl, newlen, p+reqlen, &tail, 1));
if (p[reqlen+tail.headersize+tail.len] != ZIP_END) { // 处理 nextdiff 对 tail 的影响
ZIPLIST_TAIL_OFFSET(zl) =
intrev32ifbe(intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))+nextdiff);
}
} else {
ZIPLIST_TAIL_OFFSET(zl) = intrev32ifbe(p-zl); // 如果插在尾部,新插入节点就是 tail
}
if (nextdiff != 0) { // 当 nextdiff != 0 时,说明后续节点的 prevlen 发生了变化,可能引发连锁更新,这里就递归修复整个链表
offset = p-zl;
zl = __ziplistCascadeUpdate(zl,p+reqlen); // 进行级联更新
p = zl+offset;
}
p += zipStorePrevEntryLength(p,prevlen); // 把新 entry 真正写入到 ziplist 中
p += zipStoreEntryEncoding(p,encoding,slen);
if (ZIP_IS_STR(encoding)) {
memcpy(p,s,slen);
} else {
zipSaveInteger(p,value,encoding);
}
ZIPLIST_INCR_LENGTH(zl,1);
return zl;
}
如上所示,为插入一个新元素的核心代码实现。这个有一个核心性能问题,即当插入的元素比较大时,下一个元素保存它需要5个字节,但是当前的下一个元素prevlen是1字节,那下一个元素就要更新长度,下一个元素的更新又可能导致再下一个元素更新,这样就引发了连锁更新。
4.3、级联更新
接下来我们来具体看一下级联更新时如何实现的:
unsigned char *__ziplistCascadeUpdate(unsigned char *zl, unsigned char *p) {
// ziplist级联更新,当中间一个元素变化时,它后面的元素可能全跟着一起变化,因为后面的元素都要保存前一个元素的长度, p传入变化的那个元素的地址
zlentry cur;
size_t prevlen, prevlensize, prevoffset; /* Informat of the last changed entry. */
size_t firstentrylen; /* Used to handle insert at head. */
size_t rawlen, curlen = intrev32ifbe(ZIPLIST_BYTES(zl));
size_t extra = 0, cnt = 0, offset;
size_t delta = 4; /* Extra bytes needed to update a entry's prevlen (5-1). */
unsigned char *tail = zl + intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl)); // 记录最后一个元素的指针
if (p[0] == ZIP_END) return zl; // 如果ziplist为空直接返回,不需要更新
zipEntry(p, &cur); /* no need for "safe" variant since the input pointer was validated by the function that returned it. */
firstentrylen = prevlen = cur.headersize + cur.len;
prevlensize = zipStorePrevEntryLength(NULL, prevlen);
prevoffset = p - zl;
p += prevlen;
while (p[0] != ZIP_END) { // 从传入p指针的下一个元素开始循环
assert(zipEntrySafe(zl, curlen, p, &cur, 0));
if (cur.prevrawlen == prevlen) break;
if (cur.prevrawlensize >= prevlensize) { // 如果p变小了,那说明当前的空间是足够的,即使由5字节变为了1字节,也不进行释放直接填充新的长度信息
if (cur.prevrawlensize == prevlensize) {
zipStorePrevEntryLength(p, prevlen);
} else {
zipStorePrevEntryLengthLarge(p, prevlen);
}
break;
}
assert(cur.prevrawlen == 0 || cur.prevrawlen + delta == prevlen);
rawlen = cur.headersize + cur.len; // 获取当前cur的实际长度
prevlen = rawlen + delta; // 计算下一个元素应该存储的长度,即当前元素的长度
prevlensize = zipStorePrevEntryLength(NULL, prevlen); // 计算存储当前元素长度需要的空间
prevoffset = p - zl;
p += rawlen;
extra += delta; // extra 统计需要额外增加的空间
cnt++; // 统计需要进行更新的元素数量
}
if (extra == 0) return zl; // 如果不需要额外扩充说明当前空间满足的,不需要更新
if (tail == zl + prevoffset) { // 本次级联更新中,最后一个被更新的 entry,如果正好就是 ziplist 的尾元素
if (extra - delta != 0) { // 如果尾部是唯一一个被更新的元素,就需要更新偏移,否则就需要更新偏移
ZIPLIST_TAIL_OFFSET(zl) =
intrev32ifbe(intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))+extra-delta);
}
} else {
ZIPLIST_TAIL_OFFSET(zl) = // 更新最后一个元素的偏移
intrev32ifbe(intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))+extra);
}
offset = p - zl; // “p”指向原始ziplist中第一个未更改的字节
zl = ziplistResize(zl, curlen + extra);
p = zl + offset;
memmove(p + extra, p, curlen - offset - 1); // 把不需要修改的内容向后移动
p += extra;
while (cnt) { // 需要修改的元素做遍历,逐个调整
zipEntry(zl + prevoffset, &cur); /* no need for "safe" variant since we already iterated on all these entries above. */
rawlen = cur.headersize + cur.len;
memmove(p - (rawlen - cur.prevrawlensize),
zl + prevoffset + cur.prevrawlensize,
rawlen - cur.prevrawlensize);
p -= (rawlen + delta);
if (cur.prevrawlen == 0) {
zipStorePrevEntryLength(p, firstentrylen);
} else {
zipStorePrevEntryLength(p, cur.prevrawlen+delta);
}
prevoffset -= cur.prevrawlen;
cnt--;
}
return zl;
}
4.4、删除节点
删除节点和添加操作的步骤类似。有以下三个步骤:
- 首先定位目标节点,并计算节点的空间长度 target-size。
- 进行进行内存移位,覆盖 target 原本的数据,然后通过内存重分配,收缩多余空间。
- 检查 next 、 next+1 等后续节点能否满足新前驱节点的编码。和添加操作一样,删除操作也可能会引起连锁更新。
4.5、遍历
可以对 ziplist 进行从前向后的遍历,或者从后先前的遍历。
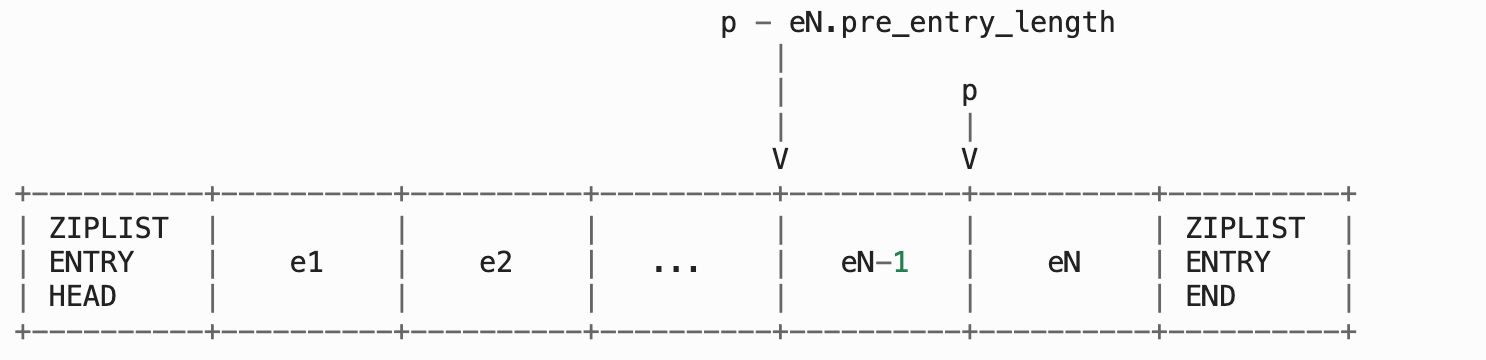
当进行从前向后的遍历时, 程序从指向节点 e1 的指针 p 开始, 计算节点 e1 的长度(e1-size), 然后将 p 加上 e1-size , 就将指针后移到了下一个节点 e2 。。。 如此反覆,直到 p 遇到 ZIPLIST_ENTRY_END 为止, 这样整个 ziplist 就遍历完了:
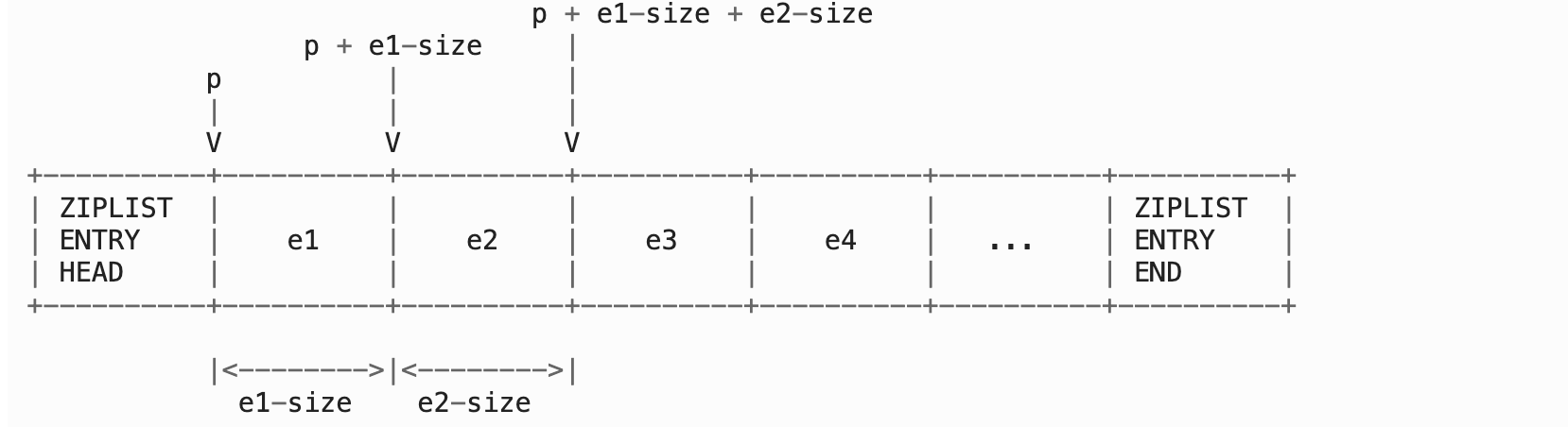
当进行从后往前遍历的时候, 程序从指向节点 eN 的指针 p 出发, 取出 eN 的 pre_entry_length 值, 然后用 p 减去 pre_entry_length , 这就将指针移动到了前一个节点 eN-1 。。。 如此反覆,直到 p 遇到 ZIPLIST_ENTRY_HEAD 为止, 这样整个 ziplist 就遍历完了。
五、压缩链表总结
ziplist 是由一系列特殊编码的内存块构成的列表,可以保存字符数组或整数值。它根据字符长度或者整数大小使用不同的编码类型,用于节约内存空间。添加和删除 ziplist 节点有可能会引起连锁更新,添加和删除操作的最坏复杂度为 O(N2)。因此在Redis的较高版本中,这个数据结构已经基本废弃不再使用,但是它在代码中仍然保留了下来,目的是为了维持和低版本的兼容性。
六、已弃用结构说明
ziplist在redis7.0被listpack所取代,同样被废弃的数据结构还有zipmap,这个结构在redis2.6之后就废弃了。但是源码依然保留了实现。还是一样仅仅是为了和低版本的RDB文件进行兼容。这也可以从 rdbLoadObject 函数中看的出来。
case RDB_TYPE_HASH_ZIPMAP:
if (!zipmapValidateIntegrity(encoded, encoded_len, 1)) {
rdbReportCorruptRDB("Zipmap integrity check failed.");
zfree(encoded);
o->ptr = NULL;
decrRefCount(o);
return NULL;
}
.....
如上所示,在加载RDB文件时,如果依然有使用了zipmap结构,就会走这个分支校验完整性并解析成字典。
「真诚赞赏,手留余香」
 WangFuJie Blog
WangFuJie Blog
真诚赞赏,手留余香
使用微信扫描二维码完成支付
