一、listpack概述
listpack 也叫紧凑列表,它的特点就是用一块连续的内存空间来紧凑地保存数据,同时为了节省内存空间,listpack 列表项使用了多种编码方式,来表示不同长度的数据,这些数据包括整数和字符串。 看描述listpack 和 ziplist 好像是一样的,其实 listpack 就是 ziplist的替代品。 相对于ziplist,listpack内存更紧凑,实现更简洁,并且解决了 ziplist 的级联更新问题。
二、listpack的构成
listpack作为ziplist的替代者,它的内存布局、实现原理和listpack非常相似。比如:都是连续的一块内存,前端都有表示内存大小、元素个数;尾部都有终结标志等元数据等。它的内存布局如下图所示:
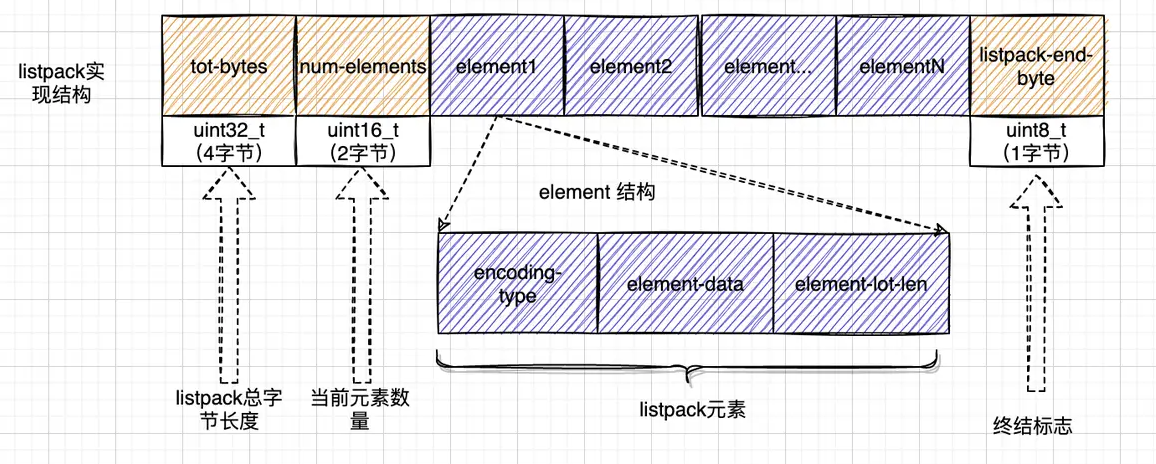
listpack 各部分解释如下:
- tot-bytes: 头部前4个字节的无符号整数记录了使用内存的大小
- num-elements: 头部第5和第6两个字节记录listpack的元素总数
- listpack-end-bytes: 存块尾部最后一个字节来表示列表的终结,内容是0xFF
我们再来看一下节点的构成,它和ziplist有明显的区别,不保存前一个节点的长度。listpack只有三个功能块:
- encoding-type: 本条目的编码方案(包含数据长度)
- element-data: 具体的数据内容
- element-lot-len: 本条目前面两个条目数据长度编码后需要的字节数
由此可以看出,listpack只保存了自己的长度信息。
三、listpack编码方案
listpack使用1个字节,对其存储的数据制定了11种编码方式。7种用于整数和整数数字组成的字符串编码,内部通过整数的方式压缩存储;3种用户普通字符串数据编码,内部直接使用原字符串的方式进行存储;1种用来表示listpack结束标识的编码。
3.1、数字编码
数字编码主要是用于整数数值和数字组成的字符串。 对于数字组成的字符串,先尝试转换为对应的整数数值,然后根据其大小范围分别采取不同的编码方式和字节长度存储。如下是7种编码规则:
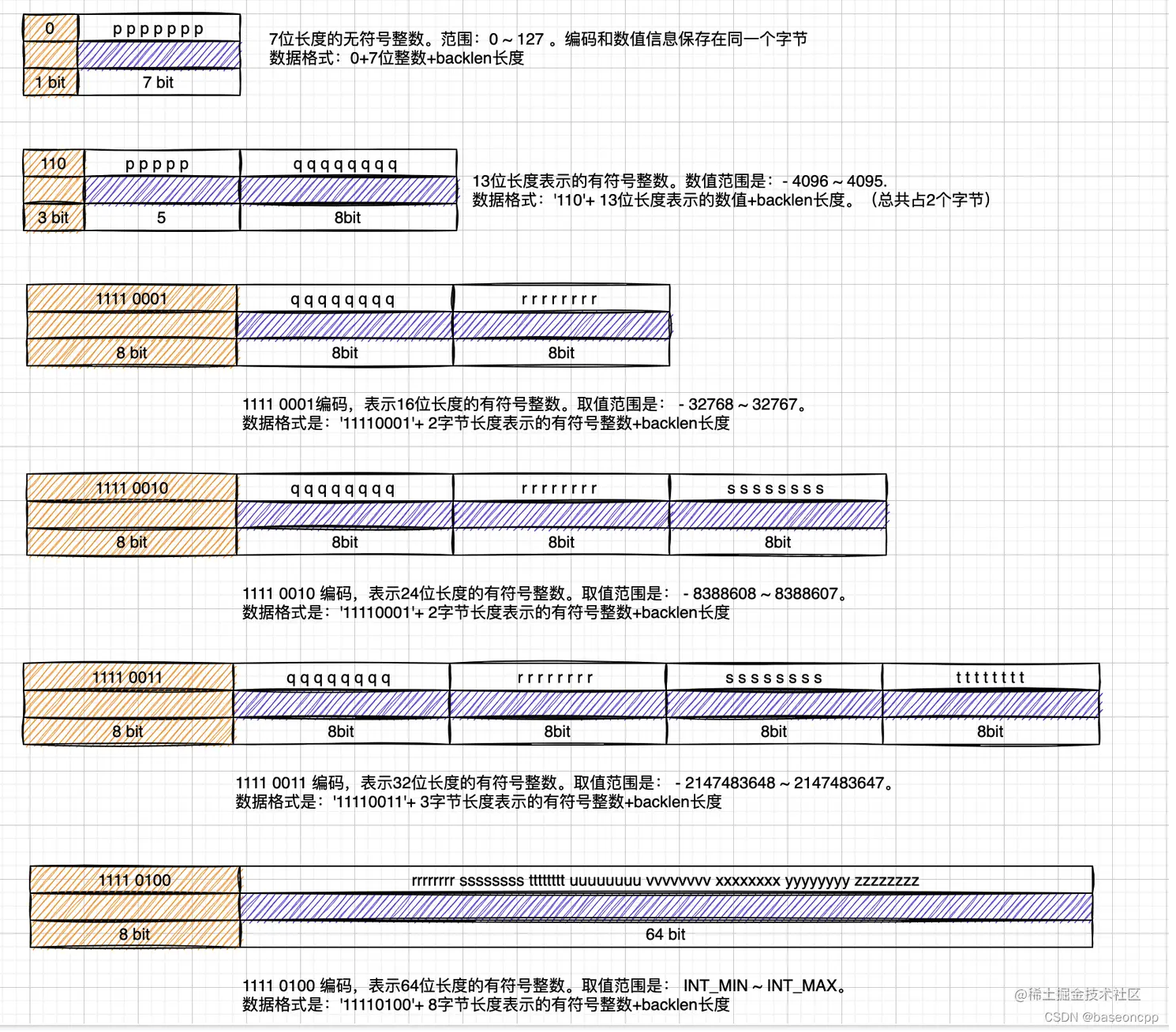
#define LP_ENCODING_7BIT_UINT 0 // 7-bit 无符号整数(0~127) 最高位是0 0xxxxxxx, 剩下7位是数据
#define LP_ENCODING_7BIT_UINT_MASK 0x80 // 10000000, 用来和最高位做判断
#define LP_ENCODING_IS_7BIT_UINT(byte) (((byte)&LP_ENCODING_7BIT_UINT_MASK)==LP_ENCODING_7BIT_UINT) // 判断这个字节是不是“7bit 整数编码”
#define LP_ENCODING_7BIT_UINT_ENTRY_SIZE 2 // 整个 entry 占 2 字节
如上所示,7为整数编码最高位标志是0, 每种编码类型都提供一个宏例如 LP_ENCODING_IS_7BIT_UINT 来这个是不是该种类型的编码。 7位整数编码的整个节点占用2字节空间,这是因为 listpack 的 entry 结构 = 数据 + backlen。 backlen占用了1个字节。backlen 记录的是“当前 entry 的总长度(从 encoding 到 content)”,不包含 backlen 自己。 针对7位整数编码,[encoding+data] 占用1字节,backlen占用1字节,其中backlen存储的是1。
3.2、字符串编码
3种字符串编码,分别根据不同的字符串长度,采取不同的编码方式。使用字符串编码的数据,其内容无法通过整数数字压缩编码:包含非数字、不可打印的二进制字符等。以下图片列出了三种字符编码规则:
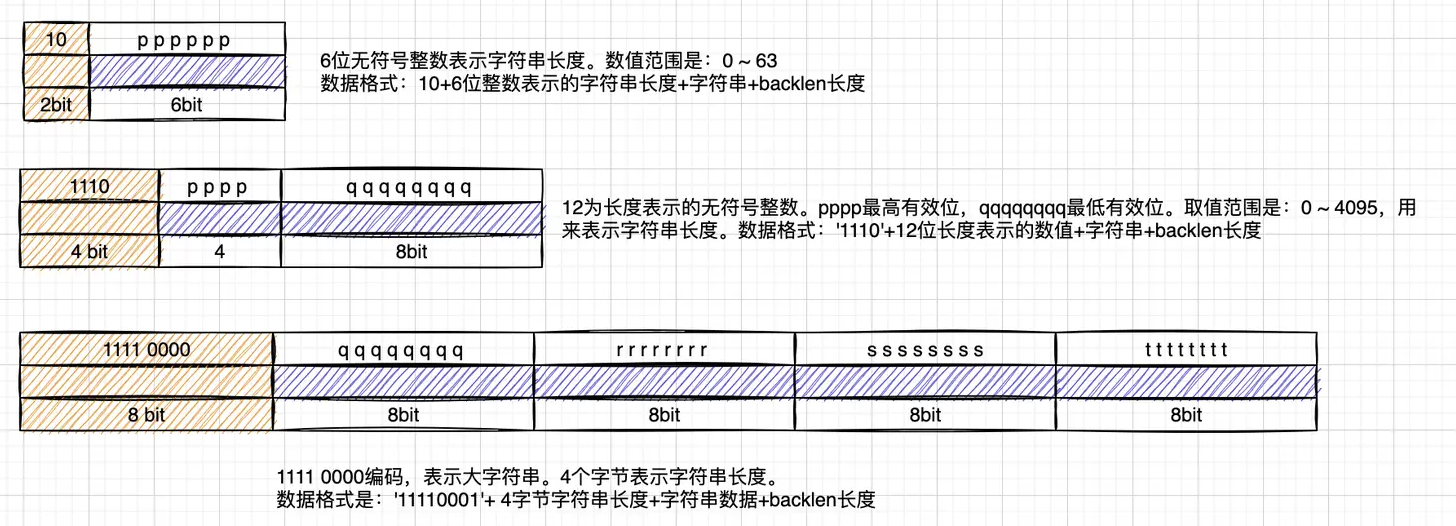
#define LP_ENCODING_6BIT_STR 0x80 // 10000000 前两位是10 表示6位字符串
#define LP_ENCODING_6BIT_STR_MASK 0xC0 // 11000000 去除最高两位
#define LP_ENCODING_IS_6BIT_STR(byte) (((byte)&LP_ENCODING_6BIT_STR_MASK)==LP_ENCODING_6BIT_STR) // 通过1字节校验是不是6位字符串编码
如上所示,编码字节的最高位是 10 就代码这是一个6位的字符串编码,剩下的6为表示字符串的长度,范围是0~63。这里没有记录整个 entry 的字节,因为字符串的长度是不固定的,和存储整数不一样。
3.3、 backlen长度编码方案
listpack每个数据元素尾部都包含一个表示当前数据长度占用总字节数的长度数据。这部分内容主要是用来从右往左遍历、搜索数据使用。其内部也采取了一种编码机制进行数据编码后存储。 下面图片描述了这中编码方式:
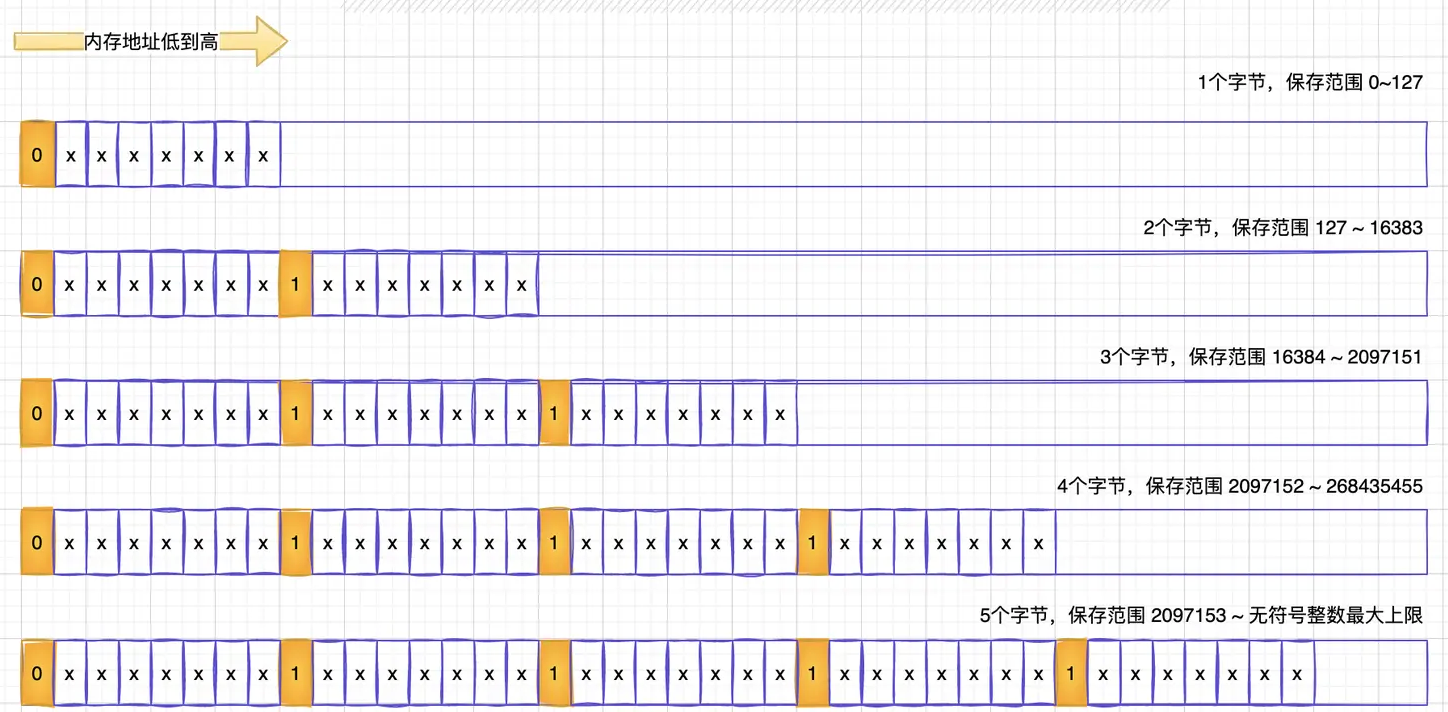
// buf写入位置(可以为 NULL,仅计算长度), l 是 entry 的长度。实现的功能是: 把一个整数 l(entry 长度)编码成“变长字节序列”,写到 buf,并返回用了多少字节
static inline unsigned long lpEncodeBacklen(unsigned char *buf, uint64_t l) {
if (l <= 127) {
if (buf) buf[0] = l; // 当长度小于等于127时,使用1字节,并在buf直接存储长度。 最高位 = 0代表backlen结束
return 1;
} else if (l < 16383) { // 长度大于127,小于16383时,使用2字节。存储方式 [高7位][低7位]
if (buf) {
buf[0] = l>>7; // 存储高7位,设置最高位为0, 表示backlen结束
buf[1] = (l&127)|128; // 存储低7位, 设置最高位 = 1
}
return 2;
}
......
}
我们这里只介绍了1字节长度和2字节长度。更多的我们省略了代码,其实实现是一致的。我们这里以为 l = 300为例,它的存储是这样的。 buf[0] = 0000010 buf[1] = 10101100
接下来我们看一下解码方式。backlen 是“从后往前解析”的, 因此它先解析第2个字节。步骤如下:
- 当前指针 → 指向 buf[1] = 10101100, 取低7位 10101100 & 01111111 = 0101100 = 44
- 判断 buf[1] 的最高位,是 1, 说明前面还有一个字节,则继续解析
- 读取前一个字节,00000010 = 2 ,最高位是0, 说明backlen结束了。
- 进行合并 (2 « 7) | 44 = 256 + 44 = 300
四、lsitpack的基本操作
4.1、创建listpack
创建1个新的listpack 使用 lpnew 函数实现,代码如下:
unsigned char *lpNew(size_t capacity) { // 新建一个listpack,如果传入了申请内存大小且大于空列表大小,就按照实际入参申请内存
unsigned char *lp = lp_malloc(capacity > LP_HDR_SIZE+1 ? capacity : LP_HDR_SIZE+1);
if (lp == NULL) return NULL;
lpSetTotalBytes(lp,LP_HDR_SIZE+1); // 设置lp的总大小为头部+结束符
lpSetNumElements(lp,0); // 设置元素个数为0
lp[LP_HDR_SIZE] = LP_EOF; // 添加结束符
return lp;
}
如上,创建新的listpack还提供了一个参数,用于预分配内存。如果参数大于7, 就按照capacity 参数大小来分配内存,如果小于7,那就申请7字节内存,刚好用于存储listpack的头部和结束符。但是无论内存分配多大,内存布局都是这样的:
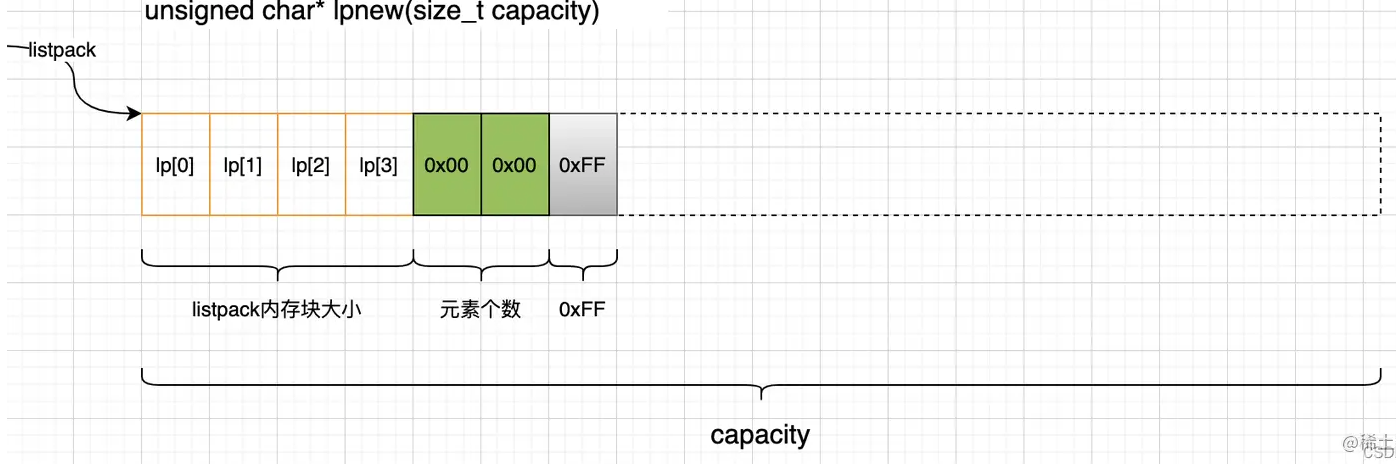
4.2、插入、更新、删除新节点
我们这里为什么把插入、更新、删除放到一起呢,因为这些数据的写操作底层都是通过一个函数实现的,那就是 lpInsert。
// 定义 lpInsert() 函数的 where 参数可能的值, 如果删除就使用空元素来替代当前元素,where传入 LP_REPLACE
#define LP_BEFORE 0
#define LP_AFTER 1
#define LP_REPLACE 2
/* 参数解释
lp: listpack 起始地址
elestr: 字符串数据 (用于处理字符串数据节点)
eleint: 整数编码数据 (用于处理整数数据节点)
size: 数据长度
p: 操作位置
where: BEFORE / AFTER / REPLACE
newp: 返回新节点位置
*/
unsigned char *lpInsert(unsigned char *lp, unsigned char *elestr, unsigned char *eleint,
uint32_t size, unsigned char *p, int where, unsigned char **newp)
{
unsigned char intenc[LP_MAX_INT_ENCODING_LEN];
unsigned char backlen[LP_MAX_BACKLEN_SIZE];
uint64_t enclen;
int delete = (elestr == NULL && eleint == NULL); // 如果没有新数据传入,设置删除标记,即这次是删除操作
if (delete) where = LP_REPLACE; // 设置where为 LP_REPLACE,即使用 NULL 替换 节点p
if (where == LP_AFTER) { // 如果where指定插入到 节点p 之后
p = lpSkip(p); // 就把p指针向后跳转一个节点,然后设置插入到 节点p 之前。
where = LP_BEFORE; // 也就是说只实现插入到指定节点前的逻辑就可以了,因此插入到指定节点后就是插入到这个节点的下一个节点之前
}
unsigned long poff = p-lp; // 记录指针p相对于 lp头的偏移量,这样一旦重新分配内存就可以根据偏移量找到p指针
int enctype;
if (elestr) { // 如果是字符串数据
enctype = lpEncodeGetType(elestr,size,intenc,&enclen); // 如果是纯数字的字符串这里也会改为整数编码,enclen = 编码后的长度
if (enctype == LP_ENCODING_INT) eleint = intenc;
} else if (eleint) {
enctype = LP_ENCODING_INT; // 如果新节点就是整型,直接用编码后的整数
enclen = size; // 参数“size”传入的是编码整数元素的长度
} else {
enctype = -1; // 这个分支是新节点既不是整数,也不是字符串。
enclen = 0;
}
unsigned long backlen_size = (!delete) ? lpEncodeBacklen(backlen,enclen) : 0; // 计算backlen, 当前 entry 需要多少字节存 backlen
uint64_t old_listpack_bytes = lpGetTotalBytes(lp); // 获取整个列表的旧长度
uint32_t replaced_len = 0;
if (where == LP_REPLACE) { // 如果是替换,计算旧 entry 总长度,
replaced_len = lpCurrentEncodedSizeUnsafe(p);
replaced_len += lpEncodeBacklenBytes(replaced_len); // 被替换节点总长度(data + backlen)
}
uint64_t new_listpack_bytes = old_listpack_bytes + enclen + backlen_size
- replaced_len; // 计算新总长度 = 旧总长度 + 新的编码长度 + 新的backlen长度 - 被替换掉元素的总长度
if (new_listpack_bytes > UINT32_MAX) return NULL; // 如果列表总长度大于4字节整数最大值,直接返回NULL,插入失败。
unsigned char *dst = lp + poff; // 通过记录的偏移量重新获取到要写入的位置
if (new_listpack_bytes > old_listpack_bytes &&
new_listpack_bytes > lp_malloc_size(lp)) {
if ((lp = lp_realloc(lp,new_listpack_bytes)) == NULL) return NULL;
dst = lp + poff; // 如果新申请了内存,通过偏移量重新获取
}
if (where == LP_BEFORE) {
memmove(dst+enclen+backlen_size,dst,old_listpack_bytes-poff); // 如果插入到目标为止之前,需要把后面的数据往后挪
} else { /* LP_REPLACE. */
memmove(dst+enclen+backlen_size, // 如果进行替换,就覆盖旧节点
dst+replaced_len,
old_listpack_bytes-poff-replaced_len);
}
if (new_listpack_bytes < old_listpack_bytes) { // 缩容重新申请内存,不需要进行素具移动
if ((lp = lp_realloc(lp,new_listpack_bytes)) == NULL) return NULL;
dst = lp + poff;
}
if (newp) {
*newp = dst; // newp写入新节点的位置,作为出参返回
if (delete && dst[0] == LP_EOF) *newp = NULL; // 如果是删除操作,且删除的是最后一个元素,给newp赋予NULL
}
if (!delete) { // 这个分支处理非删除操作
if (enctype == LP_ENCODING_INT) { // 如果是整数编码,直接把整数值拷贝到目标为止
memcpy(dst,eleint,enclen);
} else if (elestr) { // 如果是字符串编码,通过 lpEncodeString 写入数据
lpEncodeString(dst,elestr,size);
} else {
redis_unreachable(); // redis_unreachable 表示“这段代码理论上绝对不可能被执行到”,用于消除警告,如果真的执行到了会触发程序崩溃
}
dst += enclen;
memcpy(dst,backlen,backlen_size); // 写 backlen
dst += backlen_size;
}
if (where != LP_REPLACE || delete) { // 更新listpack的头信息,
uint32_t num_elements = lpGetNumElements(lp);
if (num_elements != LP_HDR_NUMELE_UNKNOWN) {
if (!delete)
lpSetNumElements(lp,num_elements+1);
else
lpSetNumElements(lp,num_elements-1);
}
}
lpSetTotalBytes(lp,new_listpack_bytes); // 更新listpack的总长度
return lp;
}
如上所示,即为listpack结构进行数据写操作的核心代码实现,上层API均是对这个函数进行的封装。从代码也可以看出 listpack 解决了 ziplist 的级联更新问题。
4.3、查找与遍历
我们已经知道为了避免级联更新,listpack 列表项只记录当前项的长度。那么 listpack 支持从左向右正向查询列表,或是从右向左反向查询列表吗? 答案当然是支持的,listpack即支持正向查询,也支持反向查询。
4.3.1、正向查询
当应用程序从左向右正向查询 listpack 时,我们可以先调用 lpFirst 函数。该函数的参数是指向 listpack 头的指针,它在执行时,会让指针向右偏移 LP_HDR_SIZE 大小,也就是跳过 listpack 头。你可以看下 lpFirst 函数的代码,如下所示:
unsigned char *lpFirst(unsigned char *lp) {
unsigned char *p = lp + LP_HDR_SIZE; // 跳过listpack头部6个字节
if (p[0] == LP_EOF) return NULL; // 如果已经是listpack的末尾结束字节,则返回NULL
return p;
}
然后,再调用 lpNext 函数,该函数的参数包括了指向 listpack 某个列表项的指针。lpNext 函数会进一步调用 lpSkip 函数,并传入当前列表项的指针,如下所示:
unsigned char *lpNext(unsigned char *lp, unsigned char *p) {
p = lpSkip(p); //调用lpSkip函数,偏移指针指向下一个列表项
if (p[0] == LP_EOF) return NULL;
return p;
}
lpSkip 函数会先后调用 lpCurrentEncodedSize 和 lpEncodeBacklen 这两个函数。
static inline unsigned char *lpSkip(unsigned char *p) {
unsigned long entrylen = lpCurrentEncodedSizeUnsafe(p);
entrylen += lpEncodeBacklenBytes(entrylen);
p += entrylen;
return p;
}
lpCurrentEncodedSize 函数是根据当前列表项第 1 个字节的取值,来计算当前项的编码类型,并根据编码类型,计算当前项编码类型和实际数据的总长度。后,lpEncodeBacklen 函数会根据编码类型和实际数据的长度之和,进一步计算列表项最后一部分 entry-len 本身的长度。 这样,lpSkip 就可以跳过当前节点的长度指向下一个节点了。
4.3.2、反向查询
我们根据 listpack 头中记录的 listpack 总长度,就可以直接定位到 listapck 的尾部结束标记。然后,我们可以调用 lpPrev 函数,该函数的参数包括指向某个列表项的指针,并返回指向当前列表项前一项的指针。
lpPrev 函数中的关键一步就是调用 lpDecodeBacklen 函数。lpDecodeBacklen 函数会从右向左,逐个字节地读取当前列表项的 entry-len。 backlen的编码解码规则我们前边已经讲述过了。通过解析backlen,就可以得到前一项的总长度,这样就可以指针指向前一项的起始位置了。
五、总结
为了减少内存开销,并进一步避免 ziplist 连锁更新问题,Redis 在 5.0 版本中,就设计实现了 listpack 结构。listpack 结构沿用了 ziplist 紧凑型的内存布局,把每个元素都紧挨着放置。Redis7.0版本彻底弃用了ziplist。
listpack 中每个列表项不再包含前一项的长度了,因此当某个列表项中的数据发生变化,导致列表项长度变化时,其他列表项的长度是不会受影响的,因而这就避免了 ziplist 面临的连锁更新问题。
「真诚赞赏,手留余香」
 WangFuJie Blog
WangFuJie Blog
真诚赞赏,手留余香
使用微信扫描二维码完成支付
