一、quicklist概述
quicklist 的设计,其实是结合了链表和 listpack 各自的优势。简单来说,一个 quicklist 就是一个链表,而链表中的每个元素又是一个 listpack (低版本中是ziplist)。快速列表是一种双向链表的数据结构。
二、quicklist结构
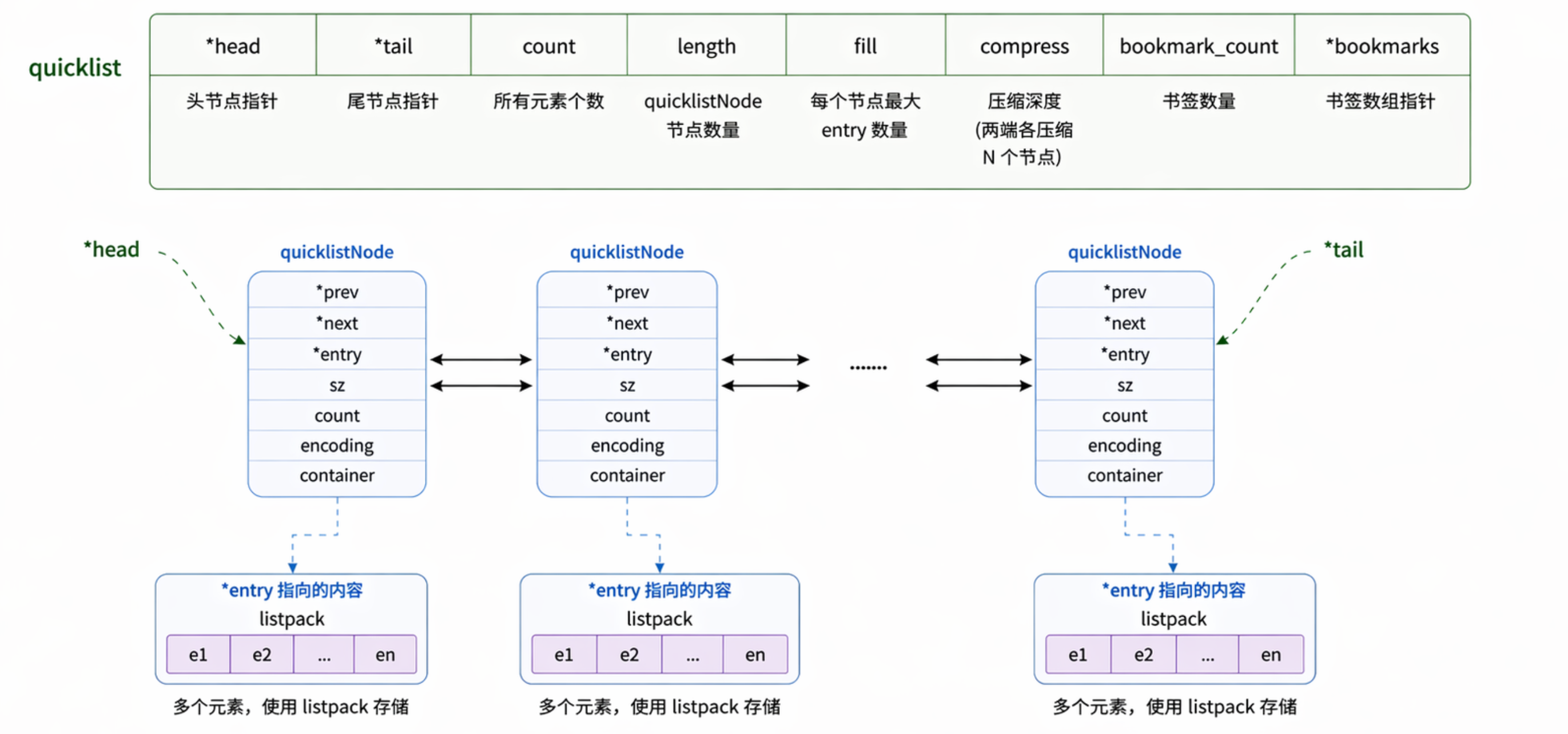
我们来看下 quicklist 的数据结构,这是在quicklist.h文件中定义的,而 quicklist 的具体实现是在quicklist.c文件中。quicklist定义如下:
typedef struct quicklist {
quicklistNode *head; // quicklist的链表头
quicklistNode *tail; // quicklist的链表尾
unsigned long count; // 所有listpack中的总元素个数
unsigned long len; //quicklistNodes的个数
size_t alloc_size; // quicklist 总共分配的内存大小(字节)
signed int fill : QL_FILL_BITS; // 控制每个 quicklistNode 里 listpack 的“填充策略” 即一个节点最多装多少元素 / 多大内存
unsigned int compress : QL_COMP_BITS; // 压缩控制 两端保留多少层节点不压缩,如compress = 2 表示 头部和尾部各 2 个 node 不压缩,中间的 node 可以压缩
unsigned int bookmark_count: QL_BM_BITS; // 当前 bookmark(书签)的数量
quicklistBookmark bookmarks[]; // 一个“可变长度数组”,存储书签
} quicklist;
从结构体的定义我们可以看到,快速列表是一个双向链表,有头结点和尾节点。这里有个元素很难理解,就是存储书签。它的本质是 quicklistNode 指针,用于快速定位某个位置。例如:你想记住某个 list 中间位置,避免每次从 head 遍历。类似“游标缓存”。
既然快速列表是一个双向链表,那它必然需要定义节点结构,它的节点就是 quicklistNode, quicklistNode 中,都包含了分别指向它前序和后序节点的指针prev和next。同时,每个 quicklistNode 又是一个 listpack:
typedef struct quicklistNode {
struct quicklistNode *prev; // 前驱节点
struct quicklistNode *next; // 后继节点
unsigned char *entry; // quicklistNode指向的listpack (也可指向ziplist,低版本使用的ziplist),也可指向一个元素,不使用列表结构
size_t sz; // listpack的字节大小
unsigned int count : 16; // listpack中的元素个数
unsigned int encoding : 2; // 编码格式,原生字节数组或压缩存储 RAW==1 or LZF==2
unsigned int container : 2; // 存储方式 PLAIN==1 or PACKED==2 (这个 quicklistNode 里面的 entry 是“一个元素”,还是“一批元素”?)
unsigned int recompress : 1; // //数据是否被压缩
unsigned int attempted_compress : 1; //数据能否被压缩
unsigned int dont_compress : 1; // 标记这个 node 不允许被压缩(即使它在压缩范围内)
unsigned int extra : 9; // 预留的bit位
} quicklistNode;
quicklistNode 结构体中还定义了一些属性,比如 listpack 的字节大小、包含的元素个数、编码格式、存储方式等,当存储的元素比较大时,可以直接存储单个元素不使用 listpack结构。
三、quicklist的基本操作
3.1、quicklist的创建
创建一个新的快速列表使用 quicklistNew函数,quicklistNew在创建新链表时需要传入一些默认参数,然后底层调用 quicklistCreate 和 quicklistSetOptions。 我们这里看 quicklistCreate 的代码实现:
quicklist *quicklistCreate(void) {
struct quicklist *quicklist;
size_t quicklist_sz;
quicklist = zmalloc_usable(sizeof(*quicklist), &quicklist_sz);
quicklist->head = quicklist->tail = NULL;
quicklist->len = 0;
quicklist->count = 0;
quicklist->alloc_size = quicklist_sz;
quicklist->compress = 0;
quicklist->fill = -2;
quicklist->bookmark_count = 0;
return quicklist;
}
如上所示,本质就是申请了quicklist结构大小的内存,然后给属性赋初值。
3.2、插入新元素
quicklist的插入操作实现比较复杂,而且功能比较多,它支持插入到头部、尾部和任意位置。插入到头部或尾部是属于push操作。
3.2.1、quicklistPush 操作
quicklistPush 函数实现了将一个新元素插入到 quicklist 的头部或尾部,通过入参where决定,如果where为QUICKLIST_HEAD就调用 quicklistPushHead, 如果where为QUICKLIST_TAIL就调用quicklistPushTail。 我们这里以插入到头部为例,看下是如何实现的:
// 向快速列表的头部节点添加新条目。 如果使用现有头部,则返回0。如果创建了新头部,则返回1。
int quicklistPushHead(quicklist *quicklist, void *value, size_t sz) {
quicklistNode *orig_head = quicklist->head; // 保存当前的头部
if (unlikely(isLargeElement(sz, quicklist->fill))) { // 判断是否是大元素,需要单独存储为一个节点。即不使用listpack
__quicklistInsertPlainNode(quicklist, quicklist->head, value, sz, 0);
return 1;
}
if (likely(
_quicklistNodeAllowInsert(quicklist->head, quicklist->fill, sz))) { // 判断当前头部是否可以继续容纳新元素
size_t oldsize = quicklist->head->sz;
quicklist->head->entry = lpPrepend(quicklist->head->entry, value, sz); // 调用lpPrepend给当前listpack 的头部添加元素
quicklistNodeUpdateSz(quicklist->head);
quicklistUpdateAllocSize(quicklist, quicklist->head->sz, oldsize);
} else {
quicklistNode *node = quicklistCreateNode(quicklist); // 需要创建新的链表节点,来存储新元素。说明原来的头部的listpack结构已经存满了
node->entry = lpPrepend(lpNew(0), value, sz);
quicklistNodeUpdateSz(node);
quicklistUpdateAllocSize(quicklist, node->sz, 0);
_quicklistInsertNodeBefore(quicklist, quicklist->head, node);
}
quicklist->count++; // quicklist的总元素个数+1
quicklist->head->count++; // 头部listpack中的元素个数+1
return (orig_head != quicklist->head);
}
这里的前置判断我们可以直接忽略,因为代码量实在太大了。
3.2.2、 quicklistInsert操作
quicklistInsert 有两个实现,分别是 quicklistInsertBefore 和 quicklistInsertAfter。底层实现是 _quicklistInsert 函数, 它的作用是 在现有条目 ’entry’ 之前或之后插入新条目。如果 after==1,则新值插入到 ’entry’ 之后,否则新值插入到 ’entry’ 之前。函数原型如下:
REDIS_STATIC void _quicklistInsert(quicklistIter *iter, quicklistEntry *entry,
void *value, const size_t sz, int after)
如上可以看到,插入到指定元素使用了quicklist迭代器,因为需要先使用迭代器遍历链表找到需要插入的位置。因此要理解这个函数,需要先看下迭代器是如何实现的。
四、quicklist迭代器
我们先看下实现迭代器的结构,涉及到两个,如下:
typedef struct quicklistIter {
quicklist *quicklist; // 指定遍历的quicklist
quicklistNode *current; // 指向当前遍历到的节点
unsigned char *zi; // 执行当前节点的 listpack 中的“当前元素位置”
long offset; // 当前元素在 listpack 中的偏移量
int direction; // 指定遍历方向
} quicklistIter;
typedef struct quicklistEntry {
const quicklist *quicklist; // 所属 quicklist
quicklistNode *node; // 当前元素所在的 quicklistNode
unsigned char *zi; // 当前元素在 listpack 中的位置(指针)
unsigned char *value; // 如果是字符串:指向字符串数据(不拷贝)
long long longval; // 如果是整数:直接解析后的整数值
size_t sz; // 当前元素长度
int offset; // 当前元素在 listpack 中的偏移量
} quicklistEntry; // 当前元素视图
迭代器使用这两个结构配合进行quicklist的遍历工作,quicklistIter控制遍历,决定下一步去哪。quicklistEntry描述当前元素,再每次next时进行更新。我们看下迭代器是如何获取下一个值的:
// 让迭代器前进一个元素,并把结果填到 entry 里。成功拿到元素返回 1 遍历结束返回 0
int quicklistNext(quicklistIter *iter, quicklistEntry *entry) {
initEntry(entry); // 把 entry 清空(value/zi/offset 等归零) 避免:上一次遍历残留数据
entry->quicklist = iter->quicklist; // 先把“属于哪个 quicklist / node写进去
entry->node = iter->current;
unsigned char *(*nextFn)(unsigned char *, unsigned char *) = NULL; // 定义辅助遍历
int offset_update = 0;
int plain = QL_NODE_IS_PLAIN(iter->current); // 判断是否是单元素节点
if (!iter->zi) { // 情况1:第一次进入当前 node, 还没定位到当前 node 的具体元素(上次跳转了节点,把zi置空了会走这个分支)
quicklistDecompressNodeForUse(iter->quicklist, iter->current); // 如果 node 被压缩(LZF),先解压
if (unlikely(plain))
iter->zi = iter->current->entry; // 如果是单元素节点,直接把 zi 指向这个唯一元素
else
iter->zi = lpSeek(iter->current->entry, iter->offset); // 如果是listpack调用lpSeek获取元素,offset = 0 → 第一个元素, -1代表最后一个元素
} else if (unlikely(plain)) {
iter->zi = NULL; // 如果当前解释是单元素 直接置 NULL,触发跳 node
} else { // 这个分支是在listpack中的普通遍历
if (iter->direction == AL_START_HEAD) { // 根据遍历方向选择函数
nextFn = lpNext;
offset_update = 1;
} else if (iter->direction == AL_START_TAIL) {
nextFn = lpPrev;
offset_update = -1;
}
iter->zi = nextFn(iter->current->entry, iter->zi); // 移动zi 指向下一个(或上一个)元素
iter->offset += offset_update; // 更新offset
}
entry->zi = iter->zi; // 把当前位置写入entry
entry->offset = iter->offset;
if (iter->zi) { // 找到了元素分支
if (unlikely(plain)) { // 单元素节点直接返回整块数据
entry->value = entry->node->entry;
entry->sz = entry->node->sz;
return 1;
}
unsigned int sz = 0;
entry->value = lpGetValue(entry->zi, &sz, &entry->longval); // 如果是listpack 就解析当前元素
entry->sz = sz;
return 1;
} else { // 如果当前 node 遍历完了,就走这个分支
quicklistCompress(iter->quicklist, iter->current); // 如果不在“两端保护区”,重新压缩d当前节点
if (iter->direction == AL_START_HEAD) { // 根据方向切换node
iter->current = iter->current->next;
iter->offset = 0;
} else if (iter->direction == AL_START_TAIL) {
iter->current = iter->current->prev;
iter->offset = -1;
}
iter->zi = NULL; // 清空zi,下一个 node 还没定位元素
return quicklistNext(iter, entry); // 跳到下一个 node → 再执行一遍逻辑
}
}
如上,我们可以看到quicklistNext这个函数是递归的,这里其实是一个很典型的“尾递归用来做状态跳转”,而不是算法上的递归。
了解完迭代器的实现,我们再看 _quicklistInsert 函数需要传入 quicklistIter 和 quicklistEntry 作为入参就很清晰了,它实现在指定元素前或之后插入新元素,需要利用迭代器先确定这个指定元素的位置。
五、quicklist的优势
为什么不直接用 listpack,当成一个“大数组”? 为什么还要在外面套一层 quicklist 呢。我们先看直接使用 listpack 有哪些不足之处。
- 一个超大的 listpack, 插入/删除是 O(N)。必须 memmove 数据。
- realloc 成本巨大,需要 拷贝整个内存块
在加上quicklist后,把一个大 list 拆成多个“小 listpack”。这样插入/删除变成“局部操作”。避免大块内存拷贝,减少 realloc 风险,支持冷热分层压缩(两端不压缩,中间压缩)。大元素单独一个 node 避免了污染整个listpack。
「真诚赞赏,手留余香」
 WangFuJie Blog
WangFuJie Blog
真诚赞赏,手留余香
使用微信扫描二维码完成支付
